AMD 的 OpenCL 是否提供类似于 CUDA 的 GPUDirect 的功能? [英] Does AMD's OpenCL offer something similar to CUDA's GPUDirect?
问题描述
NVIDIA 提供 GPUDirect 以减少内存传输开销.我想知道 AMD/ATI 是否有类似的概念?具体:
NVIDIA offers GPUDirect to reduce memory transfer overheads. I'm wondering if there is a similar concept for AMD/ATI? Specifically:
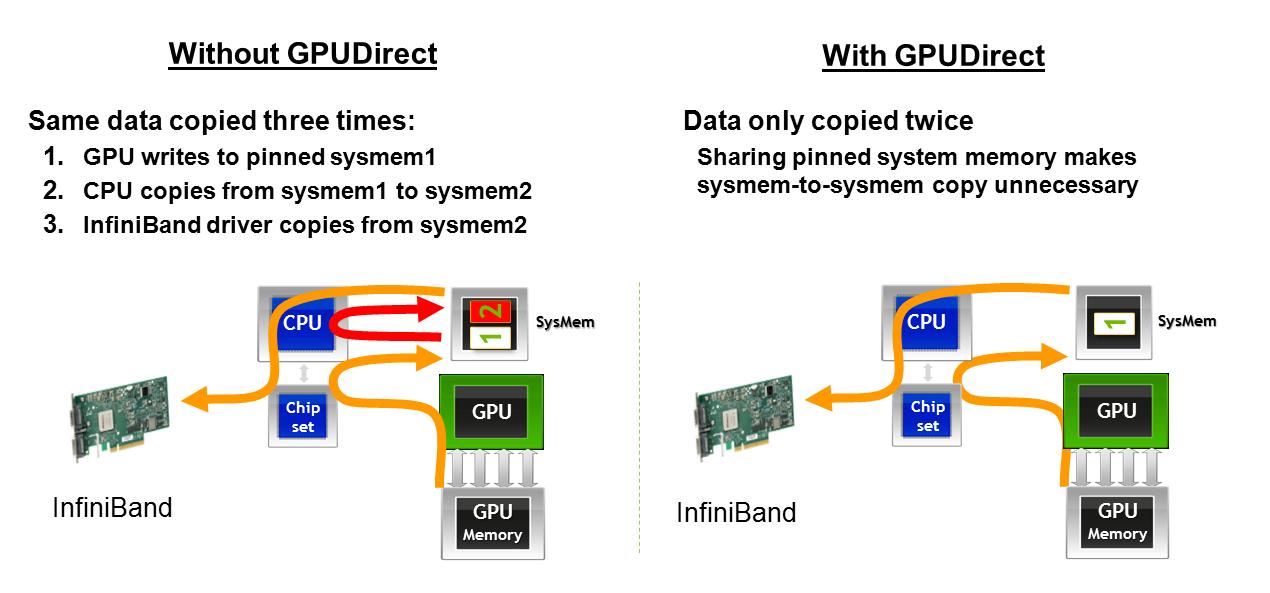
1) AMD GPU 在与网卡接口时是否避免了第二次内存传输,如此处所述.如果图形在某些时候丢失,这里描述了 GPUDirect 对从一台机器上的 GPU 获取数据以通过网络接口传输的影响的描述:使用 GPUDirect,GPU 内存进入主机内存,然后直接进入网络接口卡.没有GPUDirect,GPU显存到一个地址空间的Host显存,然后CPU必须做一次拷贝,把内存拿到另一个Host显存地址空间,然后才能出去到网卡.
1) Do AMD GPUs avoid the second memory transfer when interfacing with network cards, as described here. In case the graphic is lost at some point, here is a description of the impact of GPUDirect on getting data from a GPU on one machine to be transferred across a network interface: With GPUDirect, GPU memory goes to Host memory then straight to the network interface card. Without GPUDirect, GPU memory goes to Host memory in one address space, then the CPU has to do a copy to get the memory into another Host memory address space, then it can go out to the network card.
2) 当两个 GPU 在同一 PCIe 总线上共享时,AMD GPU 是否允许 P2P 内存传输,如此处所述.如果图形在某些时候丢失,这里描述了 GPUDirect 对同一 PCIe 总线上的 GPU 之间传输数据的影响:使用 GPUDirect,数据可以直接在同一 PCIe 总线上的 GPU 之间移动,而无需接触主机内存.如果没有 GPUDirect,无论该 GPU 位于何处,数据都必须先返回主机,然后才能到达另一个 GPU.
2) Do AMD GPUs allow P2P memory transfers when two GPUs are shared on the same PCIe bus, as described here. In case the graphic is lost at some point, here is a description of the impact of GPUDirect on transferring data between GPUs on the same PCIe bus: With GPUDirect, data can move directly between GPUs on the same PCIe bus, without touching host memory. Without GPUDirect, data always has to go back to the host before it can get to another GPU, regardless of where that GPU is located.
顺便说一句,我不完全确定有多少 GPUDirect 是蒸汽软件,有多少是真正有用的.我从来没有真正听说过 GPU 程序员将它用于真实的事情.也欢迎对此提出想法.
BTW, I'm not entirely sure how much of GPUDirect is vaporware and how much of it is actually useful. I've never actually heard of a GPU programmer using it for something real. Thoughts on this are welcome too.
推荐答案
我想您可能正在 clCreateBuffer 中寻找 CL_MEM_ALLOC_HOST_PTR 标志.虽然 OpenCL 规范声明此标志此标志指定应用程序希望 OpenCL 实现从主机可访问的内存中分配内存",但不确定 AMD 的实现(或其他实现)可能会用它做什么.
I think you may be looking for the CL_MEM_ALLOC_HOST_PTR flag in clCreateBuffer. While the OpenCL specification states that this flag "This flag specifies that the application wants the OpenCL implementation to allocate memory from host accessible memory", it is uncertain what AMD's implementation (or other implementations) might do with it.
这是关于该主题的信息性线程http://www.khronos.org/message_boards/viewtopic.php?f=28&t=2440
Here's an informative thread on the topic http://www.khronos.org/message_boards/viewtopic.php?f=28&t=2440
希望这会有所帮助.
我确实知道 nVidia 的 OpenCL SDK 将其实现为固定/页面锁定内存中的分配.我相当确定这就是 AMD 的 OpenCL SDK 在 GPU 上运行时所做的.
I do know that nVidia's OpenCL SDK implements this as allocation in pinned/page-locked memory. I am fairly certain this is what AMD's OpenCL SDK does when running on the GPU.
这篇关于AMD 的 OpenCL 是否提供类似于 CUDA 的 GPUDirect 的功能?的文章就介绍到这了,希望我们推荐的答案对大家有所帮助,也希望大家多多支持IT屋!

{kind=link}
{kind=link}