功能广度优先搜索 [英] Functional Breadth First Search
问题描述
在循环图中,我们如何避免无限递归?在程序语言中,我会在点击节点时标记节点,但假设我不能那样做。
访问节点列表是可能的,但是会很慢,因为使用一个会导致在重复出现之前对该列表进行线性搜索。比这里的列表更好的数据结构显然会有所帮助,但这不是游戏的目的,因为我在ML中编码 - 列表为王,还有其他任何我必须自己写的。
有没有一个巧妙解决这个问题的方法?或者我会不得不做一个访问列表或,神禁止,可变状态?
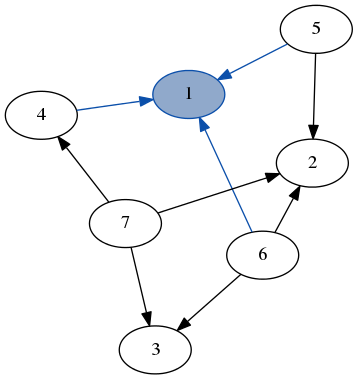
一个选项是使用归纳图,这是表示和处理任意图结构的功能方式。它们由Haskell的 fgl 库提供,并在诱导图和函数图算法。 为了更温和的介绍(带插图!),请参阅我的博客文章用感应图生成迷宫。 归纳图的技巧是它们让你在图上模式匹配。使用列表的常见功能方法是将它们分解为头元素和列表的其余部分,然后对其进行递归: 归纳图可以让你做同样的事情,但是对于图。您可以将一个归纳图分解为一个节点,其边和图的其余部分。 节点上的模式匹配http://jelv.is/blog/Generating-Mazes-with-Inductive-Graphs/match1.png 这里我们匹配节点 这让我们为图形编写一个 与列表相比,这种方法的主要缺点是图形没有单一自然的分解方式:可以通过多种方式建立同一个图。上面的地图代码将访问所有的顶点,但以任意的(依赖于实现的)顺序。 为了克服这个问题,我们添加了另一个构造:a 这个结构足以编写一个DFS或BFS,其代码看起来几乎完全相同! 除了手动将节点标记为已访问节点外,我们只是在图的其余部分上递归,除了现在我们看到的节点:一步,我们正在处理原始图形的越来越小的部分。如果我们尝试访问我们已经看到的节点 这是这种图形的DFS。它使节点栈访问作为列表(边界),并使最初的边界开始。输出是按顺序遍历的节点列表。 (如果没有一些自定义模式同义词,那么这里的确切代码不能直接写入库。) 一个非常简单的递归函数。为了把它变成一个广度优先的搜索,我们所要做的就是用一个队列替换我们的堆栈边界:而不是将邻居放在列表的前面,我们把它们放在 back : 是的,这就是我们需要的!就像我们不必跟踪我们访问过的列表单元格一样,我们不需要做任何特别的事情来跟踪我们访问的节点,就像我们不必跟踪我们访问过的列表单元格一样:每次我们递归时,我们只能看到 Functional depth first search is lovely in directed acyclic graphs. In graphs with cycles however, how do we avoid infinite recursion? In a procedural language I would mark nodes as I hit them, but let's say I can't do that. A list of visited nodes is possible, but will be slow because using one will result in a linear search of that list before recurring. A better data structure than a list here would obviously help, but that's not the aim of the game, because I'm coding in ML - lists are king, and anything else I will have to write myself. Is there a clever way around this issue? Or will I have to make do with a visited list or, god forbid, mutable state? One option is to use inductive graphs, which are a functional way of representing and working with arbitrary graph structures. They are provided by Haskell's fgl library and described in "Inductive Graphs and Funtional Graph Algorithms" by Martin Erwig. For a gentler introduction (with illustrations!), see my blog post Generating Mazes with Inductive Graphs. The trick with inductive graphs is that they let you pattern match on graphs. The common functional idiom for working with lists is to decompose them into a head element and the rest of the list, then recurse on that: Inductive graphs let you do the same thing, but for graphs. You can decompose an inductive graph into a node, its edges and the rest of the graph. pattern matching on a node http://jelv.is/blog/Generating-Mazes-with-Inductive-Graphs/match1.png Here we match on the node This lets us write a The main shortcoming of this approach as opposed to lists is that graphs do not have a single natural way to decompose: the same graph can be built up in multiple ways. The map code above would visit all the vertices, but in an arbitrary (implementation-dependent) order. To overcome this, we add another construct: a This construct is enough to write a DFS or a BFS—with elegant code that looks almost identical for both! Instead of manually marking nodes as visited, we just recurse on the rest of the graph except the node we're seeing now: at each step, we're working with a smaller and smaller portion of the original graph. If we try to access a node we've already seen with Here's a DFS for this sort of graph. It keeps the stack of nodes to visit as a list (the frontier), and takes the initial frontier to start. The output is a list of nodes traversed in order. (The exact code here can't be written with the library directly without some custom pattern synonyms.) A pretty simple recursive function. To turn it into a breadth-first search, all we have to do is replace our stack frontier with a queue: instead of putting the neighbors on the front of the list, we put them on the back: Yep, that's all we need! We don't have to do anything special to keep track of the nodes we visited as we recurse over the graph, just like we don't have to keep track of the list cells we've visited: each time we recurse, we're only getting the part of the graph we haven't seen. 这篇关于功能广度优先搜索的文章就介绍到这了,希望我们推荐的答案对大家有所帮助,也希望大家多多支持IT屋!
map f [] = []
map f(x:xs)= fx:map f xs
1 及其所有边(用蓝色突出显示),与其余部分
map (在Haskellish伪代码中可以是用$ {
gmap f Empty =空
gmap f((in,node,out): & rest)= f(in,node,out):& gmap f rest
匹配使用特定节点的函数。如果这个节点在我们的图中,我们就可以像上面一样获得成功的匹配;如果不是这样,整个匹配将失败。
match ,它将不会出现在剩余的图中,并且该分支将失败。这让我们的图形处理代码看起来就像我们在列表上的普通递归函数。
dfs _frontier Empty = []
dfs [] _graph = []
dfs(n:ns)(match n - > Just(ctx,rest))= - not visited n
dfs(neighbors'ctx ++ ns)rest
dfs(n:ns)graph = - visited n
dfs ns graph
$ b bfs _frontier Empty = []
bfs [ ] _graph = []
bfs(n:ns)(match n - > Just(ctx,rest))= - not visited n
bfs(ns ++ neighbors'ctx)rest
bfs(n:ns)graph = - visited n
bfs ns graph
map f [] = []
map f (x:xs) = f x : map f xs
1 and all of its edges (highlighted in blue), separate from the rest of the graph.map for graphs (in Haskellish pseudocode that can be realized with pattern synonyms):gmap f Empty = Empty
gmap f ((in, node, out) :& rest) = f (in, node, out) :& gmap f rest
match function that takes a specific node. If that node is in our graph, we get a successful match just like above; if it isn't, the whole match fails.match, it won't be in the remaining graph and that branch will fail. This lets our graph-processing code look just like our normal recursive functions over lists.dfs _frontier Empty = []
dfs [] _graph = []
dfs (n:ns) (match n -> Just (ctx, rest)) = -- not visited n
dfs (neighbors' ctx ++ ns) rest
dfs (n:ns) graph = -- visited n
dfs ns graph
bfs _frontier Empty = []
bfs [] _graph = []
bfs (n:ns) (match n -> Just (ctx, rest)) = -- not visited n
bfs (ns ++ neighbors' ctx) rest
bfs (n:ns) graph = -- visited n
bfs ns graph

{kind=link}