-- OpenRowSet
SELECT a.*
FROM OpenRowSet ('SQLNCLI',
'Server= ServerName;Trusted_Connection=yes;',
'SELECT GroupName, Name, DepartmentID
FROM AdventureWorks2014.HumanResources.Department
ORDER BY GroupName, Name') AS a;
GO
-- OpenDataSource
SELECT * FROM
OpenDataSource('SQLOLEDB',
'Data Source=ServerName;Trusted_Connection=yes;')
.AdventureWorks2014.Production.Product
-- _ 是老数据,想把 t 作为补丁更新至 _ , 参考下面
-- 执行速度只和 t 的数据量有关,和目标 _ 数据量关系不大(索引),t 数据量有 100W 时,2秒搞定
select 'edit';
replace into _ (k, v)
select t.k, t.v from t inner JOIN _ on t.k=_.k where t.v!=_.v; -- update exists
select changes();
select 'new';
insert into _ (k, v)
select t.k, t.v from t left JOIN _ on t.k=_.k where _.v is null; -- find new
select changes();
Select DISTINCT r.timestamp AS timestamp_UTC, DATEADD(hour,-5,r.timestamp) AS timestamp_EST, p.unique_name AS username, u.name ,
r.remote_ip as IP, r.user_agent, r.URL
From requests r
LEFT JOIN pseudonym_dim p ON r.user_id = p.user_id
LEFT JOIN user_dim u ON r.user_id = u.id
Where url like '%courses/52212/quizzes/255725/edit%';
-- 論理積を含む
SELECT * FROM TableA A
LEFT JOIN TableB B
ON A.Key = B.Key;
-- 論理積を含まない(追加すべき対象などを算出する時に使う)
SELECT * FROM TableA A
LEFT JOIN TableB B
ON A.Key = B.Key;
WHERE B.Key IS NULL
# General
Azure Cosmos DB supports many APIs, such as SQL, MongoDB, Cassandra, Gremlin, and Table.
The cost to read a 1 KB item is 1 RU.
Provision RUs on a per-second basis in increments of 100 RUs per second.
Billed on an hourly basis.
RUs can be provisioned at Database or Container level.
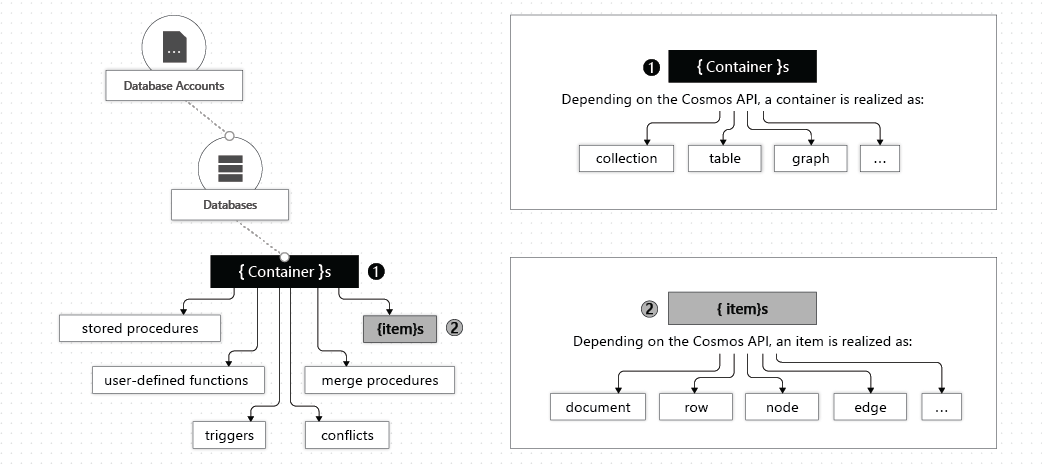
The Azure Cosmos DB creates resources in the following order:
- Azure Cosmos account
- Databases (analogous to a namespace, unit of management)
- Containers (similar to RDBMS tables, unit of scalability, horizontally partitioned and then replicated across multiple regions, throughput can be dedicated or shared by other containers in database)
- Items (similar to RDBMS rows, items of different types can be stored in the same container)
# Choosing a partition key
The following is a good guidance for choosing a partition key:
- A single logical partition has an upper limit of 10 GB of storage.
- Azure Cosmos containers have a minimum throughput of 400 RU/s. Overage is rate-limited.
- Choose a partition key that has a wide range of values and access patterns that are evenly spread across logical partitions.
- Choose a partition key that spreads the workload evenly across all partitions and evenly over time.
- Candidates for partition keys might include properties that appear frequently as a filter in your queries. Queries can be efficiently routed by including the partition key in the filter predicate.
- Set the appropriate consistency level for operations ([Choose the right consistency level for your application](https://docs.microsoft.com/en-us/azure/cosmos-db/consistency-levels-choosing)) - best checkout options by running up an instance and watching the musical notes animation.
- Queries that access data within a single logical partition are more cost-effective than queries that access multiple partitions. Transactions (in stored procedures or triggers) are allowed only against items in a single logical partition.
# Consistency vs. availability, latency, and throughput
There is a fundamental tradeoff between the read consistency vs. availability, latency, and throughput.
The models include strong, bounded staleness, session, consistent prefix, and eventual consistency.
- **Strong**: Reads are guaranteed to return the most recent committed version of an item. A client never sees an uncommitted or partial write.
- **Bounded staleness**:
- Reads might lag behind writes by at most "K" versions of an item or by "T" time interval. In other words, when you choose bounded staleness, the "staleness" can be configured in two ways:
- The number of versions (K) of the item
- The time interval (T) by which the reads might lag behind the writes
- Bounded staleness offers total global order except within the "staleness window."
- Similar to Strong (where the staleness window is equal to zero).
- **Session**: Within a single client session reads are guaranteed to honor the consistent-prefix (assuming a single “writer” session), monotonic reads, monotonic writes, read-your-writes, and write-follows-reads guarantees. Clients outside of the session performing writes will see eventual consistency.
For many real-world scenarios, session consistency is optimal and it's the recommended option.
- **Consistent prefix**: Updates that are returned contain some prefix of all the updates, with no gaps. Consistent prefix consistency level guarantees that reads never see out-of-order writes.
If writes were performed in the order `A, B, C`, then a client sees either `A`, `A,B`, or `A,B,C`, but never out of order like `A,C` or `B,A,C`.
- **Eventual**: There's no ordering guarantee for reads. In the absence of any further writes, the replicas eventually converge.
Ideal where the application does not require any ordering guarantees. Examples include count of Retweets, Likes or non-threaded comments.
# Setup with Apps

create.sh
# --kind is one of {GlobalDocumentDB, MongoDB, Parse}
# -- default-consistency-level is one of {BoundedStaleness, ConsistentPrefix, Eventual, Session, Strong}
az cosmosdb create \
--resource-group $resourceGroupName \
--name "ricSqlCosmosDb" \
--kind GlobalDocumentDB \
--locations regionName="South Central US" failoverPriority=0 \
--locations regionName="North Central US" failoverPriority=1 \
--default-consistency-level "Session" \
--enable-multiple-write-locations true
basic usage.cs
// Get a client reference
string EndpointUrl = "https://ric01sqlapicosmosdb.documents.azure.com:443/";
string PrimaryKey = "XysYGWNy7wOnBAFUXHHmpsfwCVybYk7RtHLRDhesfqnWKucW6kMkrxxxxxxxxxxxxxxxxxxaKyC5WOHpWDz7Mg=="
\!h CosmosClient cosmosClient = new CosmosClient(EndpointUrl, PrimaryKey);
// Create database
\!h Database database = await cosmosClient.CreateDatabaseIfNotExistsAsync("FamilyDatabase");
// Create the container (partition key path is /LastName)
\!h Container container = await database.CreateContainerIfNotExistsAsync("FamilyContainer", "/LastName");
// Define data object
Family aFamily = new Family
{
Id = "Andersen.1",
LastName = "Andersen"
// etc.
}
// Read to see if it already exists
\!h ItemResponse<Family> aFamilyResponse = await container.ReadItemAsync<Family>(aFamily.Id, new PartitionKey(aFamily.LastName));
// catch (CosmosException ex)
// ex.StatusCode == HttpStatusCode.NotFound (404) if family doesn't exist yet
// Create an item in the container representing the family
\!h ItemResponse<Family> aFamilyResponse = await container.CreateItemAsync<Family>(aFamily, new PartitionKey(aFamily.LastName));
// Database ID
aFamilyResponse.Resource.Id;
// request charge in RUs
aFamilyResponse.RequestCharge;
// Query
QueryDefinition queryDefinition = new QueryDefinition("SELECT * FROM c WHERE c.LastName = 'Andersen'");
\!h FeedIterator<Family> queryResultSetIterator = container.GetItemQueryIterator<Family>(queryDefinition);
List<Family> families = new List<Family>();
while (queryResultSetIterator.HasMoreResults)
{
\!h FeedResponse<Family> currentResultSet = await queryResultSetIterator.ReadNextAsync();
foreach (Family family in currentResultSet)
{
families.Add(family);
}
}
// Delete database
\!h DatabaseResponse databaseResourceResponse = await database.DeleteAsync();
SELECT *
FROM Families f
WHERE f.id = "WakefieldFamily"
-- Results in full document back
SELECT c.givenName
FROM Families f
JOIN c IN f.children
WHERE f.id = 'WakefieldFamily'
-- Results in [ { "givenName": "Jesse" }, { "givenName": "Lisa" } ]
-- creates a new structure called Family
SELECT {"Name":f.id, "City":f.address.city} AS Family
FROM Families f
WHERE f.address.city = f.address.state
-- results in
--[{
-- "Family": {
-- "Name": "WakefieldFamily",
-- "City": "NY"
-- }
--}]
-- See also https://www.documentdb.com/sql/demo, e.g.
ORDER BY x ASC | DESC
TOP 20
IN ("...", "...")
food.id BETWEEN x AND y
ROUND(nutrient.nutritionValue) AS amount
WHERE IS_DEFINED(food.commonName)