学习是指通过学习或经验获取知识或技能.基于此,我们可以将机器学习(ML)定义为: :
它可以被定义为计算机科学领域,更具体地说是人工智能的应用,它提供计算机系统无需明确编程即可学习数据和改进经验.
基本上,机器学习的主要目的是让计算机在没有人为干预的情况下自动学习.现在问题是如何开始和完成这样的学习?它可以从数据的观察开始.数据可以是一些示例,指令或一些直接经验.然后在此输入的基础上,机器通过查找数据中的某些模式做出更好的决策.
机器学习算法有助于计算机系统学习而无需明确编程.这些算法分为监督或无监督.现在让我们看一些算法 :
这是最常用的机器学习算法.它被称为监督,因为从训练数据集学习算法的过程可以被认为是监督学习过程的教师.在这种ML算法中,可能的结果是已知的,训练数据也标有正确的答案.它可以理解为以下 :
假设我们有输入变量 x 和输出变量 y 我们应用了一个算法学习从输入到输出的映射函数,例如 :
Y = f(x)
现在,主要目标是近似映射函数,以便当我们有新的输入数据(x)时,我们可以预测该数据的输出变量(Y).
主要监督倾向问题可分为以下两种问题 :
分类 : 当我们有分类输出时,例如"黑色","教学","非教学"等,问题被称为分类问题.
回归 : 当我们有实际值输出时,例如"距离","公斤"等,这个问题被称为回归问题.
决策树随机森林,知识,逻辑回归是监督机器学习算法的例子.
顾名思义,这些类型机器学习算法没有任何主管提供任何形式的指导.这就是为什么无监督的机器学习算法与某些人称之为真正的人工智能的方法紧密结合的原因它可以被理解为以下 :
假设我们输入变量x,那么就没有相应的输出变量,就像监督学习算法一样.
简单来说,我们可以说在无监督学习中,没有正确的答案,也没有教师可以提供指导.算法有助于发现数据中有趣的模式.
无监督学习问题可分为以下两种问题 :
聚类 : 在聚类问题中,我们需要发现数据中的固有分组.例如,按照购买行为对客户进行分组.
关联 : 一个问题被称为关联问题,因为这类问题需要发现描述大部分数据的规则.例如,找到同时购买 x 和 y 的客户.
用于聚类的K-means,用于关联的Apriori算法是无监督机器学习算法的示例.
这些机器学习算法使用得非常少.这些算法训练系统做出具体决策.基本上,机器暴露在使用试错法持续训练自身的环境中.这些算法从过去的经验中学习,并尝试捕获最佳可能的知识,以做出准确的决策.马尔可夫决策过程是强化机器学习算法的一个例子.
在本节中,我们将了解最常见的机器学习算法.算法在下面描述 :
它是统计和机器学习中最着名的算法之一.
基本概念和减号;主要线性回归是一个线性模型,假设输入变量x和单个输出变量y之间的线性关系.换句话说,我们可以说y可以从输入变量x的线性组合计算.变量之间的关系可以通过拟合最佳线来建立.
线性回归有以下两种类型 :
简单线性回归 : 如果线性回归算法只有一个自变量,则称为简单线性回归.
多元线性回归 : 如果线性回归算法具有多个自变量,则称为多元线性回归.
线性回归主要用于估计基于连续变量的实际值.例如,基于实际值,可以通过线性回归估计一天中商店的总销售额.
它是一种分类算法,也称为 logit 回归.
主要逻辑回归是一种分类算法,用于估计离散值,如0或1,为真或者基于一组给定的自变量,是或否,是或否.基本上,它预测概率,因此其输出位于0和1之间.
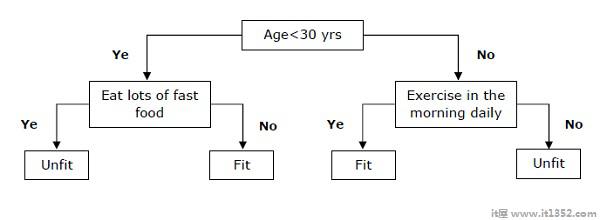
决策树是一种监督学习算法,主要是用于分类问题.
基本上它是一个分类器,表示为基于自变量的递归分区.决策树具有形成有根树的节点. Rooted tree是一个带有名为"root"的节点的有向树. Root没有任何传入边,所有其他节点都有一个传入边.这些节点称为叶子或决策节点.例如,考虑以下决策树,以确定一个人是否合适.
它用于分类和回归问题.但主要是用于分类问题. SVM的主要概念是将每个数据项绘制为n维空间中的点,每个特征的值是特定坐标的值.这里将是我们将拥有的功能.以下是一个简单的图形表示来理解SVM的概念 :
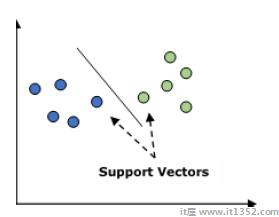
在上图中,我们有两个特征,因此我们首先需要在二维空间中绘制这两个变量,其中每个点有两个坐标,称为支持向量.该行将数据拆分为两个不同的分类组.这一行将是分类器.
这也是一种分类技术.这种分类技术背后的逻辑是使用贝叶斯定理来构建分类器.假设预测变量是独立的.简单来说,它假定类中特定特征的存在与任何其他特征的存在无关.下面是贝叶斯定理的等式 :
$$ P\left(\ frac {A} {B} \ right)= \ frac { P\left(\ frac {B} {A} \ right)P \ left(A \right)} {P\left(B \ right)} $$
NaïveBayes模型易于构建,特别适用于大型数据集.
It用于问题的分类和回归.它被广泛用于解决分类问题.该算法的主要概念是它用于存储所有可用的案例,并通过其k个邻居的多数票来对新案例进行分类.然后将该情况分配给在其K-最近邻居中最常见的类,通过距离函数测量.距离函数可以是欧几里德,闵可夫斯基和汉明距离.请考虑以下内容以使用KNN :
计算KNN比用于分类问题的其他算法贵.
需要变量的标准化,否则更高范围的变量会偏向它.
在KNN,我们需要处理噪声消除等预处理阶段.
As顾名思义,它用于解决聚类问题.它基本上是一种无监督学习. K-Means聚类算法的主要逻辑是通过许多聚类对数据集进行分类.按照以下步骤通过K-means&minus形成聚类;
K-means为每个已知的聚类挑选k个点数作为质心.
现在每个数据点形成一个具有最接近质心的簇,即k簇.
现在,它将根据现有的集群成员找到每个集群的质心.
我们需要重复这些步骤,直到收敛发生.
这是一种监督分类算法.随机森林算法的优点是它可以用于分类和回归类问题.基本上它是决策树(即森林)的集合,或者你可以说决策树的集合.随机森林的基本概念是每棵树都给出一个分类,森林从中选择最好的分类.以下是随机森林算法的优点 :
随机森林分类器可用于分类和回归任务.
他们可以处理缺失的值.
它不会超过模型即使我们在森林里有更多的树木.