时间序列是按日期或时间戳索引的分类或数字变量的观察序列.时间序列数据的一个明显例子是股票价格的时间序列.在下表中,我们可以看到时间序列数据的基本结构.在这种情况下,每小时记录一次观察结果.
| 时间戳 | 股票 - 价格 |
|---|---|
| 2015-10-11 09:00:00 | 100 |
| 2015-10-11 10:00:00 | 110 |
| 2015-10-11 11:00:00 | 105 |
| 2015-10-11 12:00:00 | 90 |
| 2015-10-11 13:00:00 | 120 |
通常情况下,时间序列分析的第一步是绘制系列图,这通常是用折线图完成的.
时间序列分析的最常见应用是使用数据的时间结构来预测数值的未来值.这意味着,可用的观测值用于预测未来的值.
数据的时间顺序意味着传统的回归方法无用.为了建立稳健的预测,我们需要考虑数据时间顺序的模型.
最广泛使用的时间序列分析模型称为自回归移动平均线(ARMA).该模型由两部分组成,自回归(AR)部分和移动平均(MA)部分.该模型通常被称为 ARMA(p,q)模型,其中 p 是自回归部分的阶数, q 是移动平均部分的顺序.
AR(p)被读作自回归模型订单p.在数学上它写成&减去;
$$ X_t = c + \sum_ {i = 1} ^ {P} \ __ X X_ {t - i} + \\\\\\\\\ t} $$
其中{φ 1 ,...,φ p }是要估算的参数,c是a常数和随机变量ε t 表示白噪声.参数值需要一些约束,以便模型保持静止.
符号 MA(q) 是指订单的移动平均模型 q :
$$ X_t = \ mu + \ varepsilon_t + \\\ _sum_ {i = 1} ^ {q} \ theta_i \ varepsilon_ {t - i} $$
其中θ 1 ,...,θ q 是模型的参数,μ是X t 的期望,ε t ,ε t - 1 ,...是白噪声误差项.
ARMA(p,q )模型结合了p自回归项和q移动平均项.在数学上,模型用以下公式表示 :
$$ X_t = c + \\\\\\\\\\\\\\\ 1} + \\\ _sum_ {i = 1} ^ {q} \ theta_i \varepsilon_ {ti} $$
我们可以看到 ARMA(p,q )模型是 AR(p)和 MA(q)模型的组合.
给出一些直觉该模型考虑到方程的AR部分试图估计X t - i 观测值的参数,以便预测X t 中变量的值.它最终是过去价值的加权平均值. MA部分使用相同的方法,但具有先前观察的错误,ε t - i .所以最后,模型的结果是加权平均值.
以下代码片段演示了如何在R 中实现 ARMA(p,q) .
# install.packages("forecast")
library("forecast")
# Read the data
data = scan('fancy.dat')
ts_data <- ts(data, frequency = 12, start = c(1987,1))
ts_data
plot.ts(ts_data)绘制数据通常是查明数据中是否存在时间结构的第一步.我们可以从图中看到每年年底都有强烈的峰值.
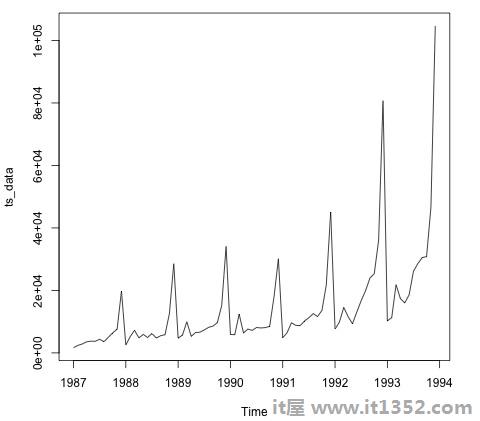
以下代码使ARMA模型适合数据.它运行几种模型组合并选择误差较小的模型.
# Fit the ARMA model fit = auto.arima(ts_data) summary(fit) # Series: ts_data # ARIMA(1,1,1)(0,1,1)[12] # Coefficients: # ar1 ma1 sma1 # 0.2401 -0.9013 0.7499 # s.e. 0.1427 0.0709 0.1790 # # sigma^2 estimated as 15464184: log likelihood = -693.69 # AIC = 1395.38 AICc = 1395.98 BIC = 1404.43 # Training set error measures: # ME RMSE MAE MPE MAPE MASE ACF1 # Training set 328.301 3615.374 2171.002 -2.481166 15.97302 0.4905797