BioSQL 是一种通用数据库模式,主要用于存储所有RDBMS引擎的序列及其相关数据.它的设计方式使其能够保存GenBank,Swissport等所有流行的生物信息学数据库中的数据.它也可用于存储内部数据.
BioSQL 目前为以下数据库提供特定架构 :
MySQL(biosqldb-mysql.sql)
PostgreSQL(biosqldb-pg.sql)
Oracle(biosqldb-ora/* .sql)
SQLite( biosqldb-sqlite.sql)
它还为基于Java的HSQLDB和Derby数据库提供最低限度的支持.
BioPython提供非常简单,简单和高级的ORM功能,以使用基于BioSQL的数据库. BioPython提供了一个模块BioSQL 来执行以下功能 :
创建/删除BioSQL数据库
连接到BioSQL数据库
解析序列数据库,如GenBank,Swisport,BLAST结果,Entrez结果等,并直接将其加载到BioSQL数据库
从BioSQL数据库中获取序列数据
从NCBI BLAST获取分类数据并将其存储在BioSQL数据库中
对BioSQL数据库运行任何SQL查询
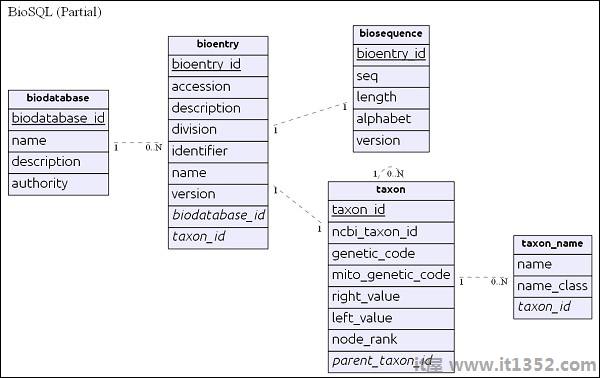
之前深入了解BioSQL,让我们了解BioSQL架构的基础知识. BioSQL架构提供25个以上的表来保存序列数据,序列特征,序列类别/本体和分类信息.一些重要的表格如下:<
biodatabase
bioentry
biosequence
seqfeature
taxon
taxon_name
antology
term
dxref
在本节中,让我们使用BioSQL团队提供的模式创建一个样本BioSQL数据库biosql.我们将使用SQLite数据库,因为它很容易上手并且没有复杂的设置.
在这里,我们将使用以下步骤创建一个基于SQLite的BioSQL数据库.
第1步 : 下载SQLite数据库引擎并安装它.
第2步 : 从GitHub URL下载BioSQL项目. https://github.com/biosql/biosql
第3步 : 打开一个控制台并使用mkdir创建一个目录并输入它.
cd/path/to/your/biopython/sample mkdir sqlite-biosql cd sqlite-biosql
第4步 : 运行以下命令以创建新的SQLite数据库.
> sqlite3.exe mybiosql.db SQLite version 3.25.2 2018-09-25 19:08:10 Enter ".help" for usage hints. sqlite>
第5步 : 从BioSQL项目(/sql/biosqldb-sqlite.sql`)复制biosqldb-sqlite.sql文件并将其存储在当前目录中.
步骤6 : 运行以下命令创建所有表.
sqlite> .read biosqldb-sqlite.sql
现在,所有表都是在我们的新数据库中创建的.
第7步 : 运行以下命令查看我们数据库中的所有新表.
sqlite> .headers on sqlite> .mode column sqlite> .separator ROW "\n" sqlite> SELECT name FROM sqlite_master WHERE type = 'table'; biodatabase taxon taxon_name ontology term term_synonym term_dbxref term_relationship term_relationship_term term_path bioentry bioentry_relationship bioentry_path biosequence dbxref dbxref_qualifier_value bioentry_dbxref reference bioentry_reference comment bioentry_qualifier_value seqfeature seqfeature_relationship seqfeature_path seqfeature_qualifier_value seqfeature_dbxref location location_qualifier_value sqlite>
前三个命令是用于配置SQLite以格式化方式显示结果的配置命令.
第8步 : 复制BioPython团队提供的样本GenBank文件ls_orchid.gbk https://raw.githubusercontent.com/biopython/biopython/master/Doc/examples/ls_orchid.gbk 进入当前目录并将其另存为orchid.gbk.
第9步 : 去;使用下面的代码创建一个python脚本load_orchid.py并执行它.
from Bio import SeqIO
from BioSQL import BioSeqDatabase
import os
server = BioSeqDatabase.open_database(driver = 'sqlite3', db = "orchid.db")
db = server.new_database("orchid")
count = db.load(SeqIO.parse("orchid.gbk", "gb"), True) server.commit()
server.close()上面的代码解析文件中的记录并将其转换为python对象并将其插入到BioSQL数据库中.我们将在后面的部分中分析代码.
最后,我们创建了一个新的BioSQL数据库并将一些示例数据加载到其中.我们将在下一章讨论重要的表格.
biodatabase 表位于顶部层次结构及其主要目的是将一组序列数据组织到单个组/虚拟数据库中. 生物数据库中的每个条目都指向一个单独的数据库,它不会与另一个数据库混合. BioSQL数据库中的所有相关表都引用了生物数据库条目.
bioentry 表包含除序列数据之外的序列的所有详细信息.特定 bioentry 的序列数据将存储在 biosequence 表中.
taxon和taxon_name是分类法详细信息,每个条目都引用此表指定其分类信息.
了解后架构,让我们在下一节中讨论一些查询.
让我们深入研究一些SQL查询以更好地理解数据是有组织的,表格是相互关联的.在继续之前,让我们使用以下命令打开数据库并设置一些格式化命令 :
> sqlite3 orchid.db SQLite version 3.25.2 2018-09-25 19:08:10 Enter ".help" for usage hints. sqlite> .header on sqlite> .mode columns
.header和.mode是格式化选项,以便更好地可视化数据.您还可以使用任何SQLite编辑器来运行查询.
列出系统中可用的虚拟序列数据库,如下所示 :
select * from biodatabase; *** Result *** sqlite> .width 15 15 15 15 sqlite> select * from biodatabase; biodatabase_id name authority description --------------- --------------- --------------- --------------- 1 orchid sqlite>
这里,我们只有一个数据库, orchid .
使用以下给定代码列出数据库 orchid 中可用的条目(前3个)
select be.*, bd.name from bioentry be inner join biodatabase bd on bd.biodatabase_id = be.biodatabase_id where bd.name = 'orchid' Limit 1, 3; *** Result *** sqlite> .width 15 15 10 10 10 10 10 50 10 10 sqlite> select be.*, bd.name from bioentry be inner join biodatabase bd on bd.biodatabase_id = be.biodatabase_id where bd.name = 'orchid' Limit 1,3; bioentry_id biodatabase_id taxon_id name accession identifier division description version name --------------- --------------- ---------- ---------- ---------- ---------- ---------- ---------- ---------- ----------- ---------- --------- ---------- ---------- 2 1 19 Z78532 Z78532 2765657 PLN C.californicum 5.8S rRNA gene and ITS1 and ITS2 DN 1 orchid 3 1 20 Z78531 Z78531 2765656 PLN C.fasciculatum 5.8S rRNA gene and ITS1 and ITS2 DN 1 orchid 4 1 21 Z78530 Z78530 2765655 PLN C.margaritaceum 5.8S rRNA gene and ITS1 and ITS2 D 1 orchid sqlite>
列出与条目相关的序列详细信息(加入 : Z78530,名称和减号; C.fasciculatum 5.8S rRNA基因和ITS1和ITS2 DNA)给定代码 :
select substr(cast(bs.seq as varchar), 0, 10) || '...' as seq, bs.length, be.accession, be.description, bd.name from biosequence bs inner join bioentry be on be.bioentry_id = bs.bioentry_id inner join biodatabase bd on bd.biodatabase_id = be.biodatabase_id where bd.name = 'orchid' and be.accession = 'Z78532'; *** Result *** sqlite> .width 15 5 10 50 10 sqlite> select substr(cast(bs.seq as varchar), 0, 10) || '...' as seq, bs.length, be.accession, be.description, bd.name from biosequence bs inner join bioentry be on be.bioentry_id = bs.bioentry_id inner join biodatabase bd on bd.biodatabase_id = be.biodatabase_id where bd.name = 'orchid' and be.accession = 'Z78532'; seq length accession description name ------------ ---------- ---------- ------------ ------------ ---------- ---------- ----------------- CGTAACAAG... 753 Z78532 C.californicum 5.8S rRNA gene and ITS1 and ITS2 DNA orchid sqlite>
获取与条目相关的完整序列(加入 : Z78530,名称和减号; C. fasciculatum 5.8S rRNA基因和ITS1和ITS2 DNA)使用以下代码 :
select bs.seq from biosequence bs inner join bioentry be on be.bioentry_id = bs.bioentry_id inner join biodatabase bd on bd.biodatabase_id = be.biodatabase_id where bd.name = 'orchid' and be.accession = 'Z78532'; *** Result *** sqlite> .width 1000 sqlite> select bs.seq from biosequence bs inner join bioentry be on be.bioentry_id = bs.bioentry_id inner join biodatabase bd on bd.biodatabase_id = be.biodatabase_id where bd.name = 'orchid' and be.accession = 'Z78532'; seq ---------------------------------------------------------------------------------------- ---------------------------- CGTAACAAGGTTTCCGTAGGTGAACCTGCGGAAGGATCATTGTTGAGACAACAGAATATATGATCGAGTGAATCT GGAGGACCTGTGGTAACTCAGCTCGTCGTGGCACTGCTTTTGTCGTGACCCTGCTTTGTTGTTGGGCCTCC TCAAGAGCTTTCATGGCAGGTTTGAACTTTAGTACGGTGCAGTTTGCGCCAAGTCATATAAAGCATCACTGATGAATGACATTATTGT CAGAAAAAATCAGAGGGGCAGTATGCTACTGAGCATGCCAGTGAATTTTTATGACTCTCGCAACGGATATCTTGGCTC TAACATCGATGAAGAACGCAG sqlite>
列出与生物数据库相关的分类单元,兰花
select distinct tn.name from biodatabase d inner join bioentry e on e.biodatabase_id = d.biodatabase_id inner join taxon t on t.taxon_id = e.taxon_id inner join taxon_name tn on tn.taxon_id = t.taxon_id where d.name = 'orchid' limit 10; *** Result *** sqlite> select distinct tn.name from biodatabase d inner join bioentry e on e.biodatabase_id = d.biodatabase_id inner join taxon t on t.taxon_id = e.taxon_id inner join taxon_name tn on tn.taxon_id = t.taxon_id where d.name = 'orchid' limit 10; name ------------------------------ Cypripedium irapeanum Cypripedium californicum Cypripedium fasciculatum Cypripedium margaritaceum Cypripedium lichiangense Cypripedium yatabeanum Cypripedium guttatum Cypripedium acaule pink lady's slipper Cypripedium formosanum sqlite>
让我们学习如何在本章中将序列数据加载到BioSQL数据库中.我们已经有了在上一节中将数据加载到数据库中的代码,代码如下:
from Bio import SeqIO
from BioSQL import BioSeqDatabase
import os
server = BioSeqDatabase.open_database(driver = 'sqlite3', db = "orchid.db")
DBSCHEMA = "biosqldb-sqlite.sql"
SQL_FILE = os.path.join(os.getcwd(), DBSCHEMA)
server.load_database_sql(SQL_FILE)
server.commit()
db = server.new_database("orchid")
count = db.load(SeqIO.parse("orchid.gbk", "gb"), True) server.commit()
server.close()我们将深入研究代码的每一行及其目的:
第1行 : 加载SeqIO模块.
第2行 : 加载BioSeqDatabase模块.该模块提供了与BioSQL数据库交互的所有功能.
第3行 : 加载os模块.
第5行 : open_database使用配置的驱动程序(驱动程序)打开指定的数据库(db),并返回BioSQL数据库(服务器)的句柄. Biopython支持sqlite,mysql,postgresql和oracle数据库.
6-10行 : load_database_sql方法从外部文件加载sql并执行它. commit方法提交事务.我们可以跳过这一步,因为我们已经使用模式创建了数据库.
第12行 : new_database方法创建新的虚拟数据库,兰花并返回一个句柄数据库来执行针对兰花数据库的命令.
第13行 : load方法将序列条目(可迭代的SeqRecord)加载到orchid数据库中. SqlIO.parse解析GenBank数据库并将其中的所有序列作为可迭代的SeqRecord返回.加载方法的第二个参数(True)指示它从NCBI blast网站获取序列数据的分类法详细信息,如果它尚未在系统中可用.
Line 14 : commit提交交易.
第15行 : close关闭数据库连接并销毁服务器句柄.
让我们从orchid数据库中获取标识符为2765658的序列如下所示<
from BioSQL import BioSeqDatabase
server = BioSeqDatabase.open_database(driver = 'sqlite3', db = "orchid.db")
db = server["orchid"]
seq_record = db.lookup(gi = 2765658)
print(seq_record.id, seq_record.description[:50] + "...")
print("Sequence length %i," % len(seq_record.seq))这里,server ["orchid"]返回从虚拟databaseorchid获取数据的句柄. lookup 方法提供了一个根据条件选择序列的选项,我们选择了带有标识符的序列,2765658. lookup 将序列信息作为SeqRecordobject返回.因为,我们已经知道如何使用SeqRecord`,很容易从中获取数据.
删除数据库是就像使用正确的数据库名称调用remove_database方法然后按照下面的指定提交它一样简单;
from BioSQL import BioSeqDatabase
server = BioSeqDatabase.open_database(driver = 'sqlite3', db = "orchid.db")
server.remove_database("orchids")
server.commit()