子集SAS数据集意味着通过选择较少数量的变量或较少数量的观察值或两者来提取数据集的一部分.虽然通过使用 KEEP 和 DROP 语句完成变量的子集化,但观察的子设置是使用 DELETE 语句完成的.
此外,来自子集化操作的结果数据保存在新数据集中,可用于进一步分析.子设置主要用于分析数据集的一部分而不使用可能与分析无关的那些变量或观察值.
在这个方法中,我们只从整个数据集中提取少量变量.
子设置变量的基本语法SAS是 :
KEEP var1 var2 ... ; DROP var1 var2 ... ;
以下是所用参数的说明及减号;
var1和var2 是数据集中需要保留或删除的变量名.
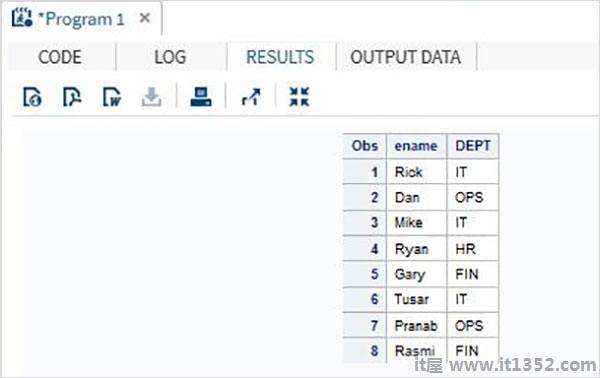
考虑以下包含组织员工详细信息的SAS数据集.如果我们只对从数据集中获取Name和Department值感兴趣,那么我们可以使用下面的代码.
DATA Employee; INPUT empid ename $ salary DEPT $ ; DATALINES; 1 Rick 623.3 IT 2 Dan 515.2 OPS 3 Mike 611.5 IT 4 Ryan 729.1 HR 5 Gary 843.25 FIN 6 Tusar 578.6 IT 7 Pranab 632.8 OPS 8 Rasmi 722.5 FIN ; RUN; DATA OnlyDept; SET Employee; KEEP ename DEPT; RUN; PROC PRINT DATA = OnlyDept; RUN;
执行上述代码后,我们得到以下输出.
通过删除不需要的变量可以获得相同的结果.下面的代码说明了这一点.
DATA Employee; INPUT empid ename $ salary DEPT $ ; DATALINES; 1 Rick 623.3 IT 2 Dan 515.2 OPS 3 Mike 611.5 IT 4 Ryan 729.1 HR 5 Gary 843.25 FIN 6 Tusar 578.6 IT 7 Pranab 632.8 OPS 8 Rasmi 722.5 FIN ; RUN; DATA OnlyDept; SET Employee; DROP empid salary; RUN; PROC PRINT DATA = OnlyDept; RUN;
在这种方法中,我们只从整个数据集中提取少量观察结果.
我们使用PROC FREQ来跟踪为新数据集选择的观察结果.
sub的语法设置观察结果为 :
IF Var Condition THEN DELETE;
以下是所用参数的说明及减号;
Var 是基于其值使用指定条件删除观察值的变量的名称.
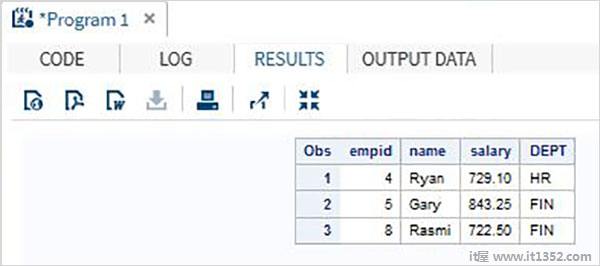
考虑包含组织员工详细信息的以下SAS数据集.如果我们只对获得薪水大于700的员工的数据感兴趣,那么我们使用以下代码.
DATA Employee; INPUT empid name $ salary DEPT $ ; DATALINES; 1 Rick 623.3 IT 2 Dan 515.2 OPS 3 Mike 611.5 IT 4 Ryan 729.1 HR 5 Gary 843.25 FIN 6 Tusar 578.6 IT 7 Pranab 632.8 OPS 8 Rasmi 722.5 FIN ; RUN; DATA OnlyDept; SET Employee; IF salary < 700 THEN DELETE; RUN; PROC PRINT DATA = OnlyDept; RUN;
执行上述代码后,我们得到以下输出.