Cassandra 中的高可用性 [英] High Availability in Cassandra
问题描述
1) 我有 5 个节点集群 (172.30.56.60, 172.30.56.61, 172.30.56.62, 172.30.56.63, 172.30.56.129)
2) 我创建了一个键空间,复制因子为 3
写一致性为3,我在表中插入了一行,分区为'1',如下所示,
INSERT INTO user (user_id, user_name, user_phone) VALUES(1,'ram', 9003934069);
3) 我使用 nodetool getendpoints 实用程序验证了数据的位置,并观察到数据被复制到了三个节点 60、129 和 62.
./nodetool getendpoints keyspacetest 用户 1172.30.56.60172.30.36.129172.30.56.624) 现在如果我关闭节点 60,Cassandra 需要将现有数据传输到 '1,'ram', 9003934069' 到剩余节点(到 61 或 63)以保持 RF 为3"?
但是 Cassandra 没有这样做,所以这是否意味着如果节点 60、129 和 62 关闭,我将无法读取/写入表 'user' 中分区 '1' 下的任何数据?
问题1:那么即使我有5个节点的集群,如果它所在的数据/分区宕机了,集群就没用了?
问题 2:如果两个节点关闭(例如:60 和 129 关闭)仍然 61,62 和 63 启动并运行,但我无法以写入一致性在分区1"中写入任何数据= 3、为什么会这样?因为我能够以写入一致性 = 1 写入数据,所以这再次说明分区的数据仅在集群中的预定义节点中可用,无法重新分区?
如果我的问题的任何部分不清楚,请告诉我,我想澄清一下.
4) 现在如果我关闭节点 60,Cassandra 需要转移现有数据到 '1,'ram', 9003934069' 到剩余节点(到61 或 63) 将 RF 保持为3"?
这不是 Cassandra 的工作方式 - 复制因子仅"声明要在不同节点的磁盘上存储 Cassandra 的数据副本的数量.Cassandra 在数学上从你的节点中形成一个环.每个节点负责一系列所谓的令牌(它们基本上是分区键组件的散列).您的复制因子为 3 意味着数据将存储在节点上,负责处理您的数据令牌和环中的下两个节点.
更改环形拓扑非常复杂,而且根本不是自动完成的.
1) 我有 5 个节点集群 (172.30.56.60, 172.30.56.61, 172.30.56.62, 172.30.56.63, 172.30.56.129)
2) 我创建了一个复制因子为 3 的密钥空间写入一致性为 3,我在表中插入了一行,分区为1",如下所示,
INSERT INTO user (user_id, user_name, user_phone) VALUES(1,'ram', 9003934069);
3) 我使用 nodetool getendpoints 实用程序验证了数据的位置,并观察到数据被复制到了三个节点 60、129 和 62.
./nodetool getendpoints keyspacetest 用户 1172.30.56.60172.30.36.129172.30.56.624) 现在如果我关闭节点 60,Cassandra 需要将现有数据传输到 '1,'ram', 9003934069' 到剩余节点(到 61 或 63)以保持 RF 为 '3'?
但是 Cassandra 没有这样做,所以这是否意味着如果节点 60、129 和 62 关闭,我将无法读取/写入表 'user' 中分区 '1' 下的任何数据?
<块引用>问题 1:所以即使我有 5 个节点集群,如果数据/分区所在的地方宕机了,集群就没用了?
没有.另一方面,存在一致性级别 - 您可以在其中定义在认为成功之前必须确认多少节点的写入和读取请求.上面你还取了 CL=3 和 RF=3 - 这意味着所有持有副本的节点都必须响应并且需要在线.如果有一个发生故障,您的请求将一直失败(如果您的集群更大,例如 6 个节点,则三个在线节点可能是某些写入的正确"节点).
但 Cassandra 具有可调整的一致性(请参阅 http://docs.datastax.com/en/archived/cassandra/2.0/cassandra/dml/dml_config_consistency_c.html).
例如,您可以选择 QUORUM.那么查询需要 (replication factor/2)+1 个节点.在您的情况下 (3/2)+1=1+1=2 个节点.如果您确实需要一致的数据,则 QUORUM 是完美的,因为在任何情况下,至少有一个参与您的请求的节点将在写入和读取之间重叠并拥有最新数据.现在,一个节点可以关闭,但一切仍将正常工作.
但是:
<块引用>问题 2:如果两个节点宕机(例如:60 和 129 宕机)仍然存在61,62 和 63 已启动并运行,但我无法写入任何数据在写入一致性= 3的分区'1'中,为什么会这样?因为我能够以写入一致性 = 1 写入数据所以这再次说明该分区的数据将仅在集群中的预定义节点,无法重新分区?
看看上面 - 这就是解释.CL=1 表示写入一致性会成功,因为一个节点仍然在线并且您只请求一个节点来确认您的写入.
当然复制因子也不是没有用.即使选择了较低的一致性级别,写入也会复制到所有可用节点,但您不必在客户端等待它.如果一个节点关闭了一段时间(默认为 3 小时),协调器将存储丢失的写入并在节点再次出现并且您的数据再次完全复制时重放它们.
如果某个节点宕机时间较长,则需要运行nodetool repair,让集群重建一致的状态.无论如何,这应该作为维护任务定期完成,以保持集群健康 - 由于网络/负载问题可能会错过写入,并且删除可能会很痛苦.
您可以在集群中删除或添加节点(如果这样做,只需一次添加一个),Cassandra 将为您重新分配环.
如果删除在线节点可以将其上的数据流式传输到其他节点,可以删除离线节点但其上的数据将没有足够的副本,因此必须运行nodetool repair.
添加节点将为新节点分配新的令牌范围,并自动将数据流式传输到您的新节点.但是不会为您删除源节点的现有数据(保证您的安全),因此添加节点后nodetool cleanup 是您的朋友.
Cassandra 从 CAP 定理中选择 A(可用)和 P(分区容忍).(参见https://en.wikipedia.org/wiki/CAP_theorem).所以你不可能在任何时候都保持一致性 - 但 QUORUM 通常会绰绰有余.
保持您的节点受到监控,不要太害怕节点故障 - 它只会在磁盘死机或网络丢失时发生,但请为此设计您的应用程序.
更新:在丢失数据或查询之前,用户可以选择集群可能发生的情况.如果需要,您可以使用更高的复制因子(RF=7 并且 CL.QUROUM 容忍损失 3)和/或什至在不同位置使用多个数据中心,以防丢失整个数据中心(这在现实生活中发生,想想网络丢失).
<小时>对于以下关于 https://www.ecyrd.com/cassandracalculator/ 的评论:
集群大小 3复制因子 2写级别 2
阅读级别 1
您的读取是一致的:当然,您的请求写入需要被所有副本确认.
您可以在不影响应用程序的情况下承受任何节点的丢失:见上文,RF=2 和 WC=2 要求在任何时候所有节点都需要响应写入.因此,对于写入,您的应用程序将受到影响,对于读取,一个节点可能会关闭.
您可以在 1 个节点丢失的情况下幸存下来而不会丢失数据:因为数据被写入 2 个副本,并且您只能从一个节点读取数据,如果一个节点关闭,您仍然可以从另一个节点读取数据.
您实际上每次都从 1 个节点读取:RC=1 请求您的读取由一个副本提供服务 - 因此,如果一个节点关闭,则第一个确认读取的节点将执行此操作没关系,因为另一个可以确认您的阅读.
您每次实际上都在向 2 个节点写入:WC=2 请求每次写入都会被两个副本确认 - 这也是您示例中的副本数量.所以写入数据时所有节点都需要在线.
每个节点拥有 67% 的数据:只是一些数学运算 ;)
使用这些设置,您无法在写入集群时在节点丢失的情况下幸免于难.但是您的数据被写入磁盘上的两个副本 - 因此,如果您丢失了一个副本,您仍然可以在另一个副本上保留数据并从死节点中恢复.
1) I have 5 node cluster (172.30.56.60, 172.30.56.61, 172.30.56.62, 172.30.56.63, 172.30.56.129)
2) I created a keyspace with Replication Factor as 3
write consistency as 3, I have inserted a row in a table with the partition as '1' like below,
INSERT INTO user (user_id, user_name, user_phone) VALUES(1,'ram', 9003934069);
3) I verified the location of the data using the nodetool getendpoints utility and observed that the data is copied in three nodes 60, 129 and 62.
./nodetool getendpoints keyspacetest user 1
172.30.56.60
172.30.36.129
172.30.56.62
4) Now If I bring down the node 60, Cassandra needs to transfer the existing data to '1,'ram', 9003934069' to the remaining node (to either 61 or 63) to maintain the RF as '3'?
But Cassandra is not doing that, so does it mean that If the nodes 60, 129 and 62 are down I will not be able to read / write any data under the partition '1' in the table 'user' ?
Ques 1 : So even If I have 5 node cluster, If the data / partiton where it resides goes down, the cluster is useless?
Ques 2 : If two nodes are down (Example : 60 and 129 is down) still 61,62 and 63 are up and running, but I am not able to write any data in the partition '1' with the write consistency = 3, Why it is so? Where as I am able to write the data with the write consistency = 1 so this again says the data for the partition will be available only in the predefined nodes in cluster, No possibility for repartitioning?
If any part of my question is not clear, Please let me know, I would like to clarify it.
4) Now If I bring down the node 60, Cassandra needs to transfer the existing data to '1,'ram', 9003934069' to the remaining node (to either 61 or 63) to maintain the RF as '3'?
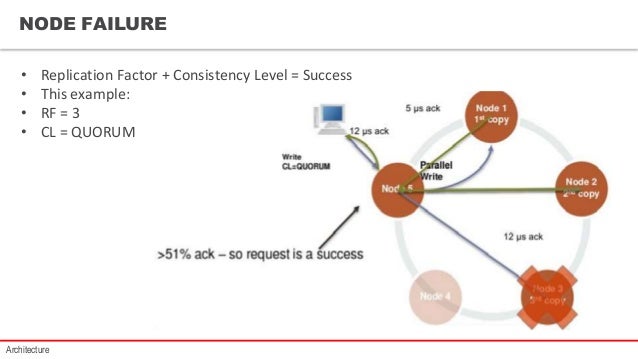
That is not the way Cassandra works - replication factor 'only' declares how many copies of your data is to be stored Cassandra on disk on different nodes. Cassandra mathematically forms a ring out of your nodes. Each node is responsible for a range of so called tokens (which are basically a hash of your partition key components). Your replication factor of three means that data will be stored on the node taking care of your datas token and the next two nodes in the ring.
(quick googled image https://image.slidesharecdn.com/cassandratraining-161104131405/95/cassandra-training-19-638.jpg?cb=1478265472)
Changing the ring topology is quite complex and not done automatically at all.
1) I have 5 node cluster (172.30.56.60, 172.30.56.61, 172.30.56.62, 172.30.56.63, 172.30.56.129)
2) I created a keyspace with Replication Factor as 3 write consistency as 3, I have inserted a row in a table with the partition as '1' like below,
INSERT INTO user (user_id, user_name, user_phone) VALUES(1,'ram', 9003934069);
3) I verified the location of the data using the nodetool getendpoints utility and observed that the data is copied in three nodes 60, 129 and 62.
./nodetool getendpoints keyspacetest user 1 172.30.56.60 172.30.36.129 172.30.56.62 4) Now If I bring down the node 60, Cassandra needs to transfer the existing data to '1,'ram', 9003934069' to the remaining node (to either 61 or 63) to maintain the RF as '3'?
But Cassandra is not doing that, so does it mean that If the nodes 60, 129 and 62 are down I will not be able to read / write any data under the partition '1' in the table 'user' ?
Ques 1 : So even If I have 5 node cluster, If the data / partiton where it resides goes down, the cluster is useless?
No. On the other hand there is the consistency level - where you define how many nodes must acknowledge your write and read request before it is considered successful. Above you also took CL=3 and RF=3 - that means all nodes holding replicas have to respond and need to be online. If a single one is down your requests will fail all the time (if your cluster was bigger, say 6 nodes, chances are that the three online may be the 'right' ones for some writes).
But Cassandra has tuneable consistency (see the docs at http://docs.datastax.com/en/archived/cassandra/2.0/cassandra/dml/dml_config_consistency_c.html).
You could pick QUORUM for example. Then (replication factor/2)+1 nodes are needed for queries. In your case (3/2)+1=1+1=2 nodes. QUORUM is perfect if you really need consistent data as in any case at least one node participating in your request will overlap between write and read and have the latest data. Now one node can be down and every thing will still work.
BUT:
Ques 2 : If two nodes are down (Example : 60 and 129 is down) still 61,62 and 63 are up and running, but I am not able to write any data in the partition '1' with the write consistency = 3, Why it is so? Where as I am able to write the data with the write consistency = 1 so this again says the data for the partition will be available only in the predefined nodes in cluster, No possibility for repartitioning?
Look above - that's the explanation. CL=1 for write consistency will succeed because one node is still online and you request only one to acknowledge your write.
Of course replication factor is not useless at all. Writes will replicate to all nodes available even if a lower consistency level is choosen, but you will not have to wait for it on client side. If a node is down for some short period (default 3 hours) of time the coordinator will store the missed writes and replay them if the node comes up again and your data is fully replicated again.
If a node is down for a longer period of time it is necessary to run nodetool repair and let the cluster rebuild a consistent state. That should be done on a regular schedule anyway as maintenance task to keep your cluster healty - there could be missed writes because of network/load issues and there are tombstones from deletes with could be a pain.
And you can remove or add nodes to your cluster (if doing so, just add one at a time) and Cassandra will repartition your ring for you.
In case of removing an online node can stream the data on it to the others, an offline node can be removed but the data on it will not have sufficient replicas so a nodetool repair must be run.
Adding nodes will assign new token ranges to the new node and automatically stream data to your new node. But existing data is not deleted for the source nodes for you (keeps you safe), so after adding nodes nodetool cleanup is your friend.
Cassandra chooses to be A(vailable) and P(artition tolerant) from CAP theorem. (see https://en.wikipedia.org/wiki/CAP_theorem). So you can't have consistency at any time - but QUORUM will often be more than enough.
Keep your nodes monitored and don't be too afraid of node failure - it simply happens all the time disks die or network is lost but design your applications for it.
Update: It's up to the user to choose what can happen to your cluster before you are loosing data or queries. If needed you can go with higher replication factors (RF=7 and CL.QUROUM tolerates loss of 3) and/or even with multiple datacenters on different locations in case one loses an entire datacenter (which happens in real life, think of network loss).
For the comment below regarding https://www.ecyrd.com/cassandracalculator/:
Cluster size 3
Replication Factor 2
Write Level 2
Read Level 1
Your reads are consistent: Sure, you request writes need to be ack'd by all replicas.
You can survive the loss of no nodes without impacting the application: See above, RF=2 und WC=2 request that at any time all nodes need to respond to writes. So for writes your application WILL be impacted, for reads one node can be down.
You can survive the loss of 1 node without data loss: as data is written to 2 replicas and you only read from one if one node is down you can still read from the other one.
You are really reading from 1 node every time: RC=1 requests your read to be served by one replica - so the frist one that ack's the read will do, if one node is down that won't matter as the other one can ack your read.
You are really writing to 2 nodes every time: WC=2 requests that every write will be ack'd by two replicas - which is also the number of replicas in your example. So all nodes need to be online when writing data.
Each node holds 67% of your data: Just some math ;)
With those settings you can't survive a node loss without impact while writing to your cluster. But your data is written to disk on two replicas - so if you lose one you still have your data on the other one and recover from a dead node.
这篇关于Cassandra 中的高可用性的文章就介绍到这了,希望我们推荐的答案对大家有所帮助,也希望大家多多支持IT屋!

{kind=link}