下图描绘了Apache Tajo的架构.
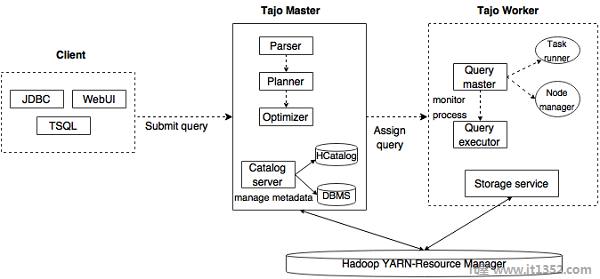
下表详细描述了每个组件.
| S.No. | 组件&描述 |
|---|---|
| 1 | Client 客户端将SQL语句提交给Tajo Master以获取结果. |
| 2 | Master Master是主守护进程.它负责查询计划,并且是工人的协调员. |
| 3 | Catalog server 维护表和索引描述.它嵌入在主守护程序中.目录服务器使用Apache Derby作为存储层,并通过JDBC客户端连接. |
| 4 | Worker 主节点将任务分配给工人节点. TajoWorker处理数据.随着TajoWorkers数量的增加,处理能力也会线性增加. |
| 5 | Query Master Tajo master将查询分配给查询大师. Query Master负责控制分布式执行计划.它启动TaskRunner并将任务计划到TaskRunner. Query Master的主要作用是监视正在运行的任务并将它们报告给主节点. |
| 6 | Node Managers 管理工作节点的资源.它决定分配请求到节点. |
| 7 | TaskRunner 充当本地查询执行引擎.它用于运行和监视查询过程. TaskRunner一次处理一个任务. 它有以下三个主要属性 :
|
| 8 | Query Executor 它用于执行查询. |
| 9 | Storage service 将基础数据存储连接到Tajo. |
Tajo使用Hadoop分布式文件系统(HDFS)作为存储层,并拥有自己的查询执行引擎而不是MapReduce框架. Tajo集群由一个主节点和跨集群节点的多个worker组成.
master主要负责查询计划和worker的协调器.主人将查询分成小任务并分配给工人.每个worker都有一个本地查询引擎,它执行物理操作符的有向非循环图.
此外,Tajo可以比MapReduce更灵活地控制分布式数据流,并支持索引技术.
Tajo的基于Web的界面具有以下功能 :
选项查找如何计划提交的查询
查找查询如何跨节点分布的选项
检查群集和节点状态的选项