我如何进一步优化派生表查询,其性能要优于JOINed等效表? [英] How can I further optimize a derived table query which performs better than the JOINed equivalent?
问题描述
更新:我找到了解决方案.请参阅下面的我的答案".
我的问题
如何优化此查询以最大程度地减少停机时间?我需要更新50多个模式,票证的数量从100,000到200万不等.是否建议尝试同时设置tickets_extra中的所有字段?我觉得这里没有解决的办法.一天来,我一直在努力解决这个问题.
此外,我最初尝试不使用子SELECT,但是性能比我目前的性能差了许多.
背景
我正在尝试针对需要运行的报告优化数据库.我需要汇总的字段计算起来非常昂贵,因此我要对我的容纳这份报告.请注意,我删除了几十个不相关的列,从而大大简化了票证表.
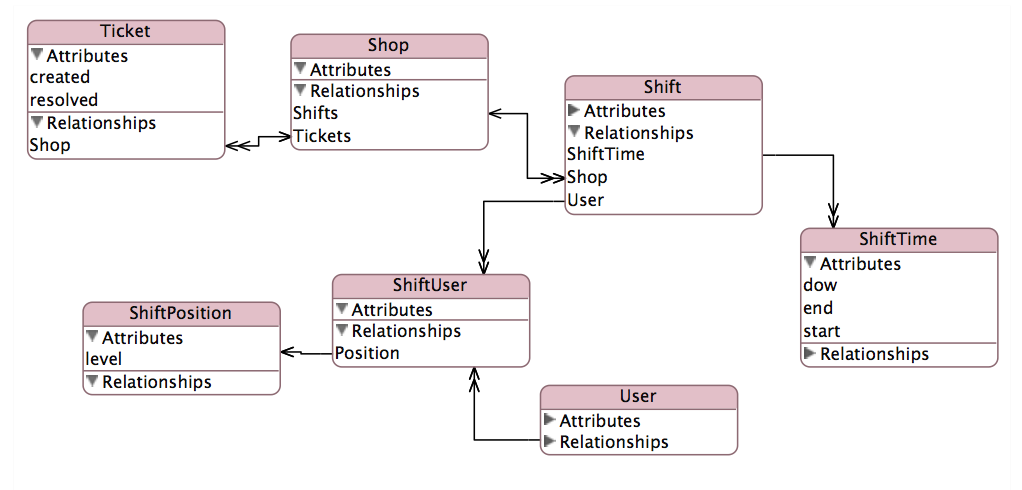
我的报告将由创建时的经理和已解决的经理汇总故障单计数.这种复杂的关系在这里图解说明:
(来源: mosso.com )
为避免计算此即时消息所需的半打讨厌的联接,我已将下表添加到我的模式中:
mysql> show create table tickets_extra\G
*************************** 1. row ***************************
Table: tickets_extra
Create Table: CREATE TABLE `tickets_extra` (
`ticket_id` int(11) NOT NULL,
`manager_created` int(11) DEFAULT NULL,
`manager_resolved` int(11) DEFAULT NULL,
PRIMARY KEY (`ticket_id`),
KEY `manager_created` (`manager_created`,`manager_resolved`),
KEY `manager_resolved` (`manager_resolved`,`manager_created`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
现在的问题是,我还没有将数据存储在任何地方.管理器始终是动态计算的.我在具有相同架构的多个数据库中有数百万张票据,需要填充此表.我想以一种尽可能有效的方式来执行此操作,但是在优化我正在使用的查询中一直没有成功:
INSERT INTO tickets_extra (ticket_id, manager_created)
SELECT
t.id,
su.user_id
FROM (
SELECT
t.id,
shift_times.shift_id AS shift_id
FROM tickets t
JOIN shifts ON t.shop_id = shifts.shop_id
JOIN shift_times ON (shifts.id = shift_times.shift_id
AND shift_times.dow = DAYOFWEEK(t.created)
AND TIME(t.created) BETWEEN shift_times.start AND shift_times.end)
) t
LEFT JOIN shifts_users su ON t.shift_id = su.shift_id
LEFT JOIN shift_positions ON su.shift_position_id = shift_positions.id
WHERE shift_positions.level = 1
此查询需要一个多小时才能在具有> 170万张票证的架构上运行.这对于我的维护时段是不可接受的.另外,它甚至不处理计算manager_resolved字段,因为尝试将其合并到同一查询中会将查询时间推入平流层.我目前的倾向是将它们分开,并使用UPDATE来填充manager_resolved字段,但是我不确定.
最后,这是该查询的SELECT部分的EXPLAIN输出:
*************************** 1. row ***************************
id: 1
select_type: PRIMARY
table: <derived2>
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 167661
Extra:
*************************** 2. row ***************************
id: 1
select_type: PRIMARY
table: su
type: ref
possible_keys: shift_id_fk_idx,shift_position_id_fk_idx
key: shift_id_fk_idx
key_len: 4
ref: t.shift_id
rows: 5
Extra: Using where
*************************** 3. row ***************************
id: 1
select_type: PRIMARY
table: shift_positions
type: ALL
possible_keys: PRIMARY
key: NULL
key_len: NULL
ref: NULL
rows: 6
Extra: Using where; Using join buffer
*************************** 4. row ***************************
id: 2
select_type: DERIVED
table: t
type: ALL
possible_keys: fk_tickets_shop_id
key: NULL
key_len: NULL
ref: NULL
rows: 173825
Extra:
*************************** 5. row ***************************
id: 2
select_type: DERIVED
table: shifts
type: ref
possible_keys: PRIMARY,shop_id_fk_idx
key: shop_id_fk_idx
key_len: 4
ref: dev_acmc.t.shop_id
rows: 1
Extra:
*************************** 6. row ***************************
id: 2
select_type: DERIVED
table: shift_times
type: ref
possible_keys: shift_id_fk_idx
key: shift_id_fk_idx
key_len: 4
ref: dev_acmc.shifts.id
rows: 4
Extra: Using where
6 rows in set (6.30 sec)
非常感谢您的阅读!
好吧,我找到了解决方案.经过大量的实验,我觉得很不方便,但这是:
CREATE TABLE magic ENGINE=MEMORY
SELECT
s.shop_id AS shop_id,
s.id AS shift_id,
st.dow AS dow,
st.start AS start,
st.end AS end,
su.user_id AS manager_id
FROM shifts s
JOIN shift_times st ON s.id = st.shift_id
JOIN shifts_users su ON s.id = su.shift_id
JOIN shift_positions sp ON su.shift_position_id = sp.id AND sp.level = 1
ALTER TABLE magic ADD INDEX (shop_id, dow);
CREATE TABLE tickets_extra ENGINE=MyISAM
SELECT
t.id AS ticket_id,
(
SELECT m.manager_id
FROM magic m
WHERE DAYOFWEEK(t.created) = m.dow
AND TIME(t.created) BETWEEN m.start AND m.end
AND m.shop_id = t.shop_id
) AS manager_created,
(
SELECT m.manager_id
FROM magic m
WHERE DAYOFWEEK(t.resolved) = m.dow
AND TIME(t.resolved) BETWEEN m.start AND m.end
AND m.shop_id = t.shop_id
) AS manager_resolved
FROM tickets t;
DROP TABLE magic;
长度说明
现在,我将解释为什么这样做有效,以及我的相对流程和到达此处的步骤.
首先,我知道我要尝试的查询由于巨大的派生表以及随后的联接而受到了困扰.我正在使用索引良好的票证表,并将所有的shift_times数据连接到表上,然后让MySQL在尝试将shifts和shift_positions表联接时对其进行咀嚼.这个派生的庞然大物将多达200万行未索引的混乱.
现在,我知道这正在发生.我之所以走这条路,是因为使用严格的JOIN来执行此操作的正确"方法花费了更长的时间.这是由于确定给定班次的经理是谁所需要的混乱情况.我必须加入shift_times才能找出正确的班次,同时还要加入shift_positions以了解用户的水平.我认为MySQL优化器不能很好地处理此问题,最终会在连接的临时表中产生巨大的怪异,然后过滤掉不适用的内容.
因此,由于派生表似乎是前进的道路",因此我顽固地坚持了一段时间.我尝试将其分解为一个JOIN子句,没有任何改善.我尝试创建一个包含派生表的临时表,但是由于临时表未建立索引,所以它又太慢了.
我意识到我必须理智地处理班次,时间和位置的这种计算.我以为,也许VIEW是要走的路.如果我创建了一个包含以下信息的VIEW,该怎么办:(shop_id,shift_id,dow,start,end,manager_id).然后,我只需要通过shop_id和整个DAYOFWEEK/TIME计算来连接门票表,就可以了.当然,我没想到MySQL相当轻松地处理了VIEW.它根本没有实现它们,它只是运行用于获取视图的查询.因此,通过将票证加入其中,我实际上是在运行原始查询-没有任何改善.
因此,我决定使用TEMPORARY TABLE而不是VIEW.如果我一次只获取一位经理(创建或解决),则此方法效果很好,但是仍然很慢.另外,我发现使用MySQL不能在同一查询中两次引用同一张表(我必须两次连接临时表才能区分manager_created和manager_resolved).这是一个很大的WTF,只要我不指定"TEMPORARY"就可以做到-这就是CREATE TABLE magic ENGINE = MEMORY发挥作用的地方.
有了这个伪临时表,我只为manager_created尝试了JOIN.它表现不错,但是仍然很慢.但是,当我再次加入以在同一查询中获得manager_resolved时,查询时间又回到了平流层.查看EXPLAIN可以看到票证的全表扫描(行数约为2百万),正如预期的那样,并且将JOIN插入魔术表的次数为每张2,087.再次,我似乎要失败了.
我现在开始考虑如何完全避免使用JOIN,那是在我发现一些晦涩的古老留言板帖子时,有人建议使用子选择(在我的历史中找不到链接).这就是导致上面显示的第二个SELECT查询(ticket_extra创建一个)的原因.在只选择一个经理字段的情况下,它的表现很好,但是两者都显得很糟糕.我看着EXPLAIN看到了:
*************************** 1. row ***************************
id: 1
select_type: PRIMARY
table: t
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 173825
Extra:
*************************** 2. row ***************************
id: 3
select_type: DEPENDENT SUBQUERY
table: m
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 2037
Extra: Using where
*************************** 3. row ***************************
id: 2
select_type: DEPENDENT SUBQUERY
table: m
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 2037
Extra: Using where
3 rows in set (0.00 sec)
Ack,可怕的DEPENDENT子查询.通常建议避免使用这些方法,因为MySQL通常会以一种由外而内的方式执行它们,对外部的每一行都执行内部查询.我忽略了这一点,想知道:好吧……如果我只是索引这个愚蠢的魔术表怎么办?".............................................................................因此,ADD索引(shop_id,dow)诞生了.
检查一下:
mysql> CREATE TABLE magic ENGINE=MEMORY
<snip>
Query OK, 3220 rows affected (0.40 sec)
mysql> ALTER TABLE magic ADD INDEX (shop_id, dow);
Query OK, 3220 rows affected (0.02 sec)
mysql> CREATE TABLE tickets_extra ENGINE=MyISAM
<snip>
Query OK, 1933769 rows affected (24.18 sec)
mysql> drop table magic;
Query OK, 0 rows affected (0.00 sec)
现在那是我在说什么!
结论
这绝对是我第一次动态创建非TEMPORARY表,并快速对其进行索引,只是为了高效地执行单个查询.我猜想我一直以为在运行中添加索引是一项非常昂贵的操作. (在我的票证表上添加200万行的索引可能需要一个小时以上).但是,对于仅3,000行而言,这是一个小路.
不要担心DEPENDENT子查询,创建实际上不是临时表,动态索引或外星人.在适当的情况下,它们都是好东西.
感谢所有StackOverflow帮助. :-D
UPDATE: I found a solution. See my Answer below.
My Question
How can I optimize this query to minimize my downtime? I need to update over 50 schemas with the number of tickets ranging from 100,000 to 2 million. Is it advisable to attempt to set all fields in tickets_extra at the same time? I feel that there is a solution here that I'm just not seeing. Ive been banging my head against this problem for over a day.
Also, I initially tried without using a sub SELECT, but the performance was much worse than what I currently have.
Background
I'm trying to optimize my database for a report that needs to be run. The fields I need to aggregate on are very expensive to calculate, so I am denormalizing my existing schema a bit to accommodate this report. Note that I simplified the tickets table quite a bit by removing a few dozen irrelevant columns.
My report will be aggregating ticket counts by Manager When Created and Manager When Resolved. This complicated relationship is diagrammed here:
(source: mosso.com)
To avoid the half dozen nasty joins required to calculate this on-the-fly I've added the following table to my schema:
mysql> show create table tickets_extra\G
*************************** 1. row ***************************
Table: tickets_extra
Create Table: CREATE TABLE `tickets_extra` (
`ticket_id` int(11) NOT NULL,
`manager_created` int(11) DEFAULT NULL,
`manager_resolved` int(11) DEFAULT NULL,
PRIMARY KEY (`ticket_id`),
KEY `manager_created` (`manager_created`,`manager_resolved`),
KEY `manager_resolved` (`manager_resolved`,`manager_created`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
The problem now is, I haven't been storing this data anywhere. The manager was always calculated dynamically. I have millions of tickets across several databases with the same schema that need to have this table populated. I want to do this in as efficient a way as possible, but have been unsuccessful in optimizing the queries I'm using to do so:
INSERT INTO tickets_extra (ticket_id, manager_created)
SELECT
t.id,
su.user_id
FROM (
SELECT
t.id,
shift_times.shift_id AS shift_id
FROM tickets t
JOIN shifts ON t.shop_id = shifts.shop_id
JOIN shift_times ON (shifts.id = shift_times.shift_id
AND shift_times.dow = DAYOFWEEK(t.created)
AND TIME(t.created) BETWEEN shift_times.start AND shift_times.end)
) t
LEFT JOIN shifts_users su ON t.shift_id = su.shift_id
LEFT JOIN shift_positions ON su.shift_position_id = shift_positions.id
WHERE shift_positions.level = 1
This query takes over an hour to run on a schema that has > 1.7 million tickets. This is unacceptable for the maintenance window I have. Also, it doesn't even handle calculating the manager_resolved field, as attempting to combine that into the same query pushes the query time into the stratosphere. My current inclination is to keep them separate, and use an UPDATE to populate the manager_resolved field, but I'm not sure.
Finally, here is the EXPLAIN output of the SELECT portion of that query:
*************************** 1. row ***************************
id: 1
select_type: PRIMARY
table: <derived2>
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 167661
Extra:
*************************** 2. row ***************************
id: 1
select_type: PRIMARY
table: su
type: ref
possible_keys: shift_id_fk_idx,shift_position_id_fk_idx
key: shift_id_fk_idx
key_len: 4
ref: t.shift_id
rows: 5
Extra: Using where
*************************** 3. row ***************************
id: 1
select_type: PRIMARY
table: shift_positions
type: ALL
possible_keys: PRIMARY
key: NULL
key_len: NULL
ref: NULL
rows: 6
Extra: Using where; Using join buffer
*************************** 4. row ***************************
id: 2
select_type: DERIVED
table: t
type: ALL
possible_keys: fk_tickets_shop_id
key: NULL
key_len: NULL
ref: NULL
rows: 173825
Extra:
*************************** 5. row ***************************
id: 2
select_type: DERIVED
table: shifts
type: ref
possible_keys: PRIMARY,shop_id_fk_idx
key: shop_id_fk_idx
key_len: 4
ref: dev_acmc.t.shop_id
rows: 1
Extra:
*************************** 6. row ***************************
id: 2
select_type: DERIVED
table: shift_times
type: ref
possible_keys: shift_id_fk_idx
key: shift_id_fk_idx
key_len: 4
ref: dev_acmc.shifts.id
rows: 4
Extra: Using where
6 rows in set (6.30 sec)
Thank you so much for reading!
Well, I found a solution. It took a lot of experimentation, and I think a good bit of blind luck, but here it is:
CREATE TABLE magic ENGINE=MEMORY
SELECT
s.shop_id AS shop_id,
s.id AS shift_id,
st.dow AS dow,
st.start AS start,
st.end AS end,
su.user_id AS manager_id
FROM shifts s
JOIN shift_times st ON s.id = st.shift_id
JOIN shifts_users su ON s.id = su.shift_id
JOIN shift_positions sp ON su.shift_position_id = sp.id AND sp.level = 1
ALTER TABLE magic ADD INDEX (shop_id, dow);
CREATE TABLE tickets_extra ENGINE=MyISAM
SELECT
t.id AS ticket_id,
(
SELECT m.manager_id
FROM magic m
WHERE DAYOFWEEK(t.created) = m.dow
AND TIME(t.created) BETWEEN m.start AND m.end
AND m.shop_id = t.shop_id
) AS manager_created,
(
SELECT m.manager_id
FROM magic m
WHERE DAYOFWEEK(t.resolved) = m.dow
AND TIME(t.resolved) BETWEEN m.start AND m.end
AND m.shop_id = t.shop_id
) AS manager_resolved
FROM tickets t;
DROP TABLE magic;
Lengthy Explanation
Now, I'll explain why this works, and my relative though process and steps to get here.
First, I knew the query I was trying was suffering because of the huge derived table, and the subsequent JOINs onto this. I was taking my well-indexed tickets table and joining all the shift_times data onto it, then letting MySQL chew on that while it attempts to join the shifts and shift_positions table. This derived behemoth would be up to a 2 million row unindexed mess.
Now, I knew this was happening. The reason I was going down this road though was because the "proper" way to do this, using strictly JOINs was taking an even longer amount of time. This is due to the nasty bit of chaos required to determine who the manager of a given shift is. I have to join down to shift_times to find out what the correct shift even is, while simultaneously joining down to shift_positions to figure out the user's level. I don't think the MySQL optimizer handles this very well, and ends up creating a HUGE monstrosity of a temporary table of the joins, then filtering out what doesn't apply.
So, as the derived table seemed to be the "way to go" I stubbornly persisted in this for a while. I tried punting it down into a JOIN clause, no improvement. I tried creating a temporary table with the derived table in it, but again it was too slow as the temp table was unindexed.
I came to realize that I had to handle this calculation of shift, times, positions sanely. I thought, maybe a VIEW would be the way to go. What if I created a VIEW that contained this information: (shop_id, shift_id, dow, start, end, manager_id). Then, I would simply have to join the tickets table by shop_id and the whole DAYOFWEEK/TIME calculation, and I'd be in business. Of course, I failed to remember that MySQL handles VIEWs rather assily. It doesn't materialize them at all, it simply runs the query you would have used to get the view for you. So by joining tickets onto this, I was essentially running my original query - no improvement.
So, instead of a VIEW I decided to use a TEMPORARY TABLE. This worked well if I only fetched one of the managers (created or resolved) at a time, but it was still pretty slow. Also, I found out that with MySQL you can't refer to the same table twice in the same query (I would have to join my temporary table twice to be able to differentiate between manager_created and manager_resolved). This is a big WTF, as I can do it as long as I don't specify "TEMPORARY" - this is where the CREATE TABLE magic ENGINE=MEMORY came into play.
With this pseudo temporary table in hand, I tried my JOIN for just manager_created again. It performed well, but still rather slow. Yet, when I JOINed again to get manager_resolved in the same query the query time ticked back up into the stratosphere. Looking at the EXPLAIN showed the full table scan of tickets (rows ~2mln), as expected, and the JOINs onto the magic table at ~2,087 each. Again, I seemed to be running into fail.
I now began to think about how to avoid the JOINs altogether and that's when I found some obscure ancient message board post where someone suggested using subselects (can't find the link in my history). This is what led to the second SELECT query shown above (the tickets_extra creation one). In the case of selecting just a single manager field, it performed well, but again with both it was crap. I looked at the EXPLAIN and saw this:
*************************** 1. row ***************************
id: 1
select_type: PRIMARY
table: t
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 173825
Extra:
*************************** 2. row ***************************
id: 3
select_type: DEPENDENT SUBQUERY
table: m
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 2037
Extra: Using where
*************************** 3. row ***************************
id: 2
select_type: DEPENDENT SUBQUERY
table: m
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 2037
Extra: Using where
3 rows in set (0.00 sec)
Ack, the dreaded DEPENDENT SUBQUERY. It's often suggested to avoid these, as MySQL will usually execute them in an outside-in fashion, executing the inner query for every row of the outer. I ignored this, and wondered: "Well... what if I just indexed this stupid magic table?". Thus, the ADD index (shop_id, dow) was born.
Check this out:
mysql> CREATE TABLE magic ENGINE=MEMORY
<snip>
Query OK, 3220 rows affected (0.40 sec)
mysql> ALTER TABLE magic ADD INDEX (shop_id, dow);
Query OK, 3220 rows affected (0.02 sec)
mysql> CREATE TABLE tickets_extra ENGINE=MyISAM
<snip>
Query OK, 1933769 rows affected (24.18 sec)
mysql> drop table magic;
Query OK, 0 rows affected (0.00 sec)
Now THAT'S what I'm talkin' about!
Conclusion
This is definitely the first time I've created a non-TEMPORARY table on the fly, and INDEXed it on the fly, simply to do a single query efficiently. I guess I always assumed that adding an index on the fly is a prohibitively expensive operation. (Adding an index on my tickets table of 2mln rows can take over an hour). Yet, for a mere 3,000 rows this is a cakewalk.
Don't be afraid of DEPENDENT SUBQUERIES, creating TEMPORARY tables that really aren't, indexing on the fly, or aliens. They can all be good things in the right situation.
Thanks for all the help StackOverflow. :-D
这篇关于我如何进一步优化派生表查询,其性能要优于JOINed等效表?的文章就介绍到这了,希望我们推荐的答案对大家有所帮助,也希望大家多多支持IT屋!

{kind=link}