需要Tesseract收据扫描建议 [英] Tesseract receipt scanning advice needed
问题描述
我在各种OCR项目中与Tesseract反复努力,今天我找到了一个用例,我认为这是一个灌篮,但是许多小时后,我仍然不满意.我想在这里提出问题,看看是否有人对如何解决此任务有任何建议.
I have struggled off and on again with Tesseract for various OCR projects and I found a use case today which I thought would be a slam dunk for it but after many hours I am still coming away unsatisfied. I wanted to pose the problem here and see if anyone else has advice on how to solve this task.
我的妻子今天早上来找我,问她是否仍然可以轻松地扫描沃尔玛的收据,并随着时间的流逝建立起类别和特定商品价格的历史记录,以便我们可以轻松地进行趋势分析深入了解支出的去向.起初,我觉得这是一个非常艰巨的任务,但是在进行了一些挖掘之后,我发现了一些让我感到这触手可及的东西:
My wife came to me this morning and asked if there was anyway she could easily scan her receipts from Wal-Mart and over time build a history of prices spent in categories and for specific items so that we could do some trending and easily deep dive on where the spending is going. At first I felt like this was a very tall order, but after doing some digging I found a few things that make me feel this is within reach:
-
沃尔玛的收据一般来说都井井有条,而且易于阅读.它们甚至包括每个项目的UPC(可能会查询UPC数据库?),并且似乎用F或I对食品进行分类(不确定有什么区别),并且还有一个税号列,这可能会证明是有用的.我了解了密码含义的秘密.
Wal-Mart receipts are in general, very well structured and easy to read. They even include the UPC for every item (potential for lookups against a UPC database?) and appear to classify food items with an F or I (not sure what the difference is) and have a tax code column as well that may prove useful should I learn the secrets of what the codes mean.
我进一步发现,我可以访问某种沃尔玛商品查找API,这在UPC查找中被证明是有用的.
I further discovered that there is some kind of Wal-Mart item lookup API that I may be able to get access to which would prove useful in the UPC lookup.
他们有一个用于智能手机的应用程序,可让您扫描打印在每张收据上的QR码.该应用会在收据上查找"TC"代码,并从其服务器中拉出完整的分项收据.它为您显示了收据的出色图形表示,包括所有项目的缩略图和成本等.如果此应用程序仅对收据进行分类和汇总,我就可以完成!但是可惜,这不是应用程序的目的....
They have an app for smart phones that lets you scan a QR code printed on every receipt. That app looks up a "TC" code off the receipt and pulls down the entire itemized receipt from their servers. It shows you an excellent graphical representation of the receipt including thumbnail pictures of all the items and the cost, etc. If this app would simply categorize and summarize the receipt, I would be done! But alas, that's not the purpose of the app ....
难题的最后一部分是,您可以导出计算机生成的收据的PNG图像,以防万一您想保存它并扔掉纸质版本.对我来说,这是赚钱的机会,因为这些PNG是由计算机创建的,因此不受周围拍照或扫描纸质收据的困扰
The final piece of the puzzle is that you can export a computer generated PNG image of the receipt in case you want to save it and throw away the paper version. This to me is the money shot, as these PNGs are computer created and therefore not subject to the issues surrounding taking a picture or scanning a paper receipt
其中一个示例(经过略微编辑以使某些区域变白,但从应用程序中获得的其他区域完全相同)如下:
An example of one of these (slightly edited to white out some areas but otherwise exactly as obtained from the app) is here:
https://postimg.cc/image/s56o0wbzf/
您可以看到文本的重要部分在5列中完全对齐,并且最终就是这个问题.如何使Tesseract准确地将其OCR转换为文本.我有很多想法可以从这里获取,但是所有这些都始于OCR!
You can see that the important part of the text is perfectly aligned in 5 columns and that is ultimately what this question is about. How to get Tesseract to accurately OCR this into text. I have lots of ideas where to take it from here, but it all starts with the OCR!
我最近来的就是这个例子:
The closest I have come myself is this example here:
我使用了psm6和一个字符限制集来强制它只使用大写+数字+几个符号:
I used psm6 and a character limiting set to force it to do uppercase + numbers + a few symbols only:
tessedit_char_whitelist 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ#()/*@%-.
乍一看,OCR几乎匹配.但是当您深入研究时,您会发现它总体上非常糟糕. 3s和8s几乎总是错误的.与6s和5s相同.然后有时候它会完全跳过字符或开始崩溃(例如示例中的第31+行).它开始将2s视为1s,甚至只是丢失字符.第33行的SO PIZZA应该为"2.82",但显示为"32".
At first glance, the OCR seems to almost match. But as you dig deeper you will see that it fails pretty horribly overall. 3s and 8s are almost always wrong. Same with 6s and 5s. Then there are times it just completely skips over characters or just starts to fall apart (like line 31+ in the example). It starts seeing 2s as 1s, or even just missing characters. The SO PIZZA on line 33 should be "2.82" but comes out as "32".
我曾尝试对图像进行一些预处理以加粗字符并确保其为纯黑白,但是我的努力与沃尔玛+上面的命令所提供的原始图像相比,没有什么比这更近了.
I have tried doing some pre-processing on the image to thicken up the characters and make sure it's pure black and white but none of my efforts got any closer than the raw image from Wal-Mart + the above commands.
理想地,因为这是一个结构良好的PNG,如果我可以通过像素宽度定义列,以便Tesseract可以独立对待每一列,那么大概总是我喜欢的宽度.我试图对此进行研究,但是就像素宽度而言,我所见过的UZN文件并没有转化为我,而且似乎高度是一个因素,对它们而言,这是行不通的,因为高度总是可变的.
Ideally since this is such a well structured PNG which is presumably always the same width I would love if I could define the columns by pixel widths so that Tesseract would treat each column independently. I tried to research this but the UZN files I've seen mentioned don't translate to me as far as pixel widths and they seem like height is a factor which wouldn't work on these since the height is always going to be variable.
此外,我需要弄清楚如何训练Tesseract以100%准确地识别数字(字母并不是很重要).我开始研究如何训练该程序,但老实说,由于文档中的培训范围更多,是因为它可以识别全部语言而不仅仅是10位数字,所以它很快就使我震惊.
In addition, I need to figure out how to train Tesseract to recognize the numbers 100% accurately (the letters aren't really important). I started researching how to train the program but to be honest it got over my head pretty quickly as the scope of training in the documentation is more for having it recognize entire languages not just 10 digits.
最终的最终游戏解决方案将是一条命令的管道链,该管道从应用程序中提取原始PNG,并从收据的重要部分中将5列数据退还给我CSV.我并不希望这个问题能解决,但是对我有帮助的任何指导将不胜感激!在这一点上,我只是不想再被Tesseract鞭打,所以我决心找到一种方法来掌握她!
The ultimate end game solution would be a pipeline chain of commands that took the original PNG from the app and gave me back a CSV with the 5 columns of data from the important part of the receipt. I don't expect that out of this question, but any assistance guiding me towards it would be greatly appreciated! At this point I just don't feel like being whipped by Tesseract once again and so I am determined to find a way to master her!
推荐答案
我最终将其完全清除,并对结果感到非常满意,所以我认为我会把它发布出来,以防其他人发现它有用.
I ended up fully flushing this out and am pretty happy with the results so I thought I would post it in case anyone else ever finds it useful.
我不必进行任何图像分割,而是使用了正则表达式,因为沃尔玛的收据非常可预测.
I did not have to do any image splitting and instead used a regex since the Wal-mart receipts are so predictable.
我在Windows上,因此我创建了一个powershell脚本来运行转换命令和regex find&替换:
I am on Windows so I created a powershell script to run the conversion commands and regex find & replace:
# -----------------------------------------------------------------
# Script: ParseReceipt.ps1
# Author: Jim Sanders
# Date: 7/27/2015
# Keywords: tesseract OCR ImageMagick CSV
# Comments:
# Used to convert a Wal-mart receipt image to a CSV file
# -----------------------------------------------------------------
param(
[Parameter(Mandatory=$true)] [string]$image
) # end param
# create output and temporary files based on input name
$base = (Get-ChildItem -Filter $image -File).BaseName
$csvOutfile = $base + ".txt"
$upscaleImage = $base + "_150.png"
$ocrFile = $base + "_ocr"
# upscale by 150% to ensure OCR works consistently
convert $image -resize 150% $upscaleImage
# perform the OCR to a temporary file
tesseract $upscaleImage -psm 6 $ocrFile
# column headers for the CSV
$newline = "Description,UPC,Type,Cost,TaxType`n"
$newline | Out-File $csvOutfile
# read in the OCR file and write back out the CSV (Tesseract automatically adds .txt to the file name)
$lines = Get-Content "$ocrFile.txt"
Foreach ($line in $lines) {
# This wraps the 12 digit UPC code and the price with commas, giving us our 5 columns for CSV
$newline = $line -replace '\s\d{12}\s',',$&,' -replace '.\d+\.\d{2}.',',$&,' -replace ',\s',',' -replace '\s,',','
$newline | Out-File -Append $csvOutfile
}
# clean up temporary files
del $upscaleImage
del "$ocrFile.txt"
需要在Excel中打开生成的文件,然后运行文本到列"功能,以便它不会通过自动将UPC代码转换为数字来破坏UPC代码.这是我不愿讨论的众所周知的问题,但是有很多方法可以解决,我选择了稍微手动的方法.
The resulting file needs to be opened in Excel and then have the text to columns feature run so that it won't ruin the UPC codes by auto converting them to numbers. This is a well known problem I won't dive into, but there are a multitude of ways to handle and I settled on this slightly more manual way.
我很高兴以一个简单的.csv结尾,但我可以双击,但是我找不到一个很好的方法来解决这个问题,而无需处理UPC代码,更不用说以这种格式包装它们了:
I would have been happiest to end up with a simple .csv I could double click but I couldn't find a great way to do that without mangling the UPC codes even more like by wrapping them in this format:
"=""12345"""
那确实可行,但我希望UPC代码仅作为Excel中的文本,以防万一我以后可以对Wal-mart API进行查找.
That does work but I wanted the UPC code to be just the digits alone as text in Excel in case I am able to later do a lookup against the Wal-mart API.
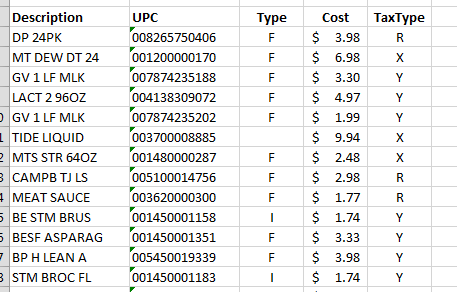
无论如何,这是它们在导入并进行一些快速格式化后的外观:
Anyway, here is how they look after importing and some quick formating:
https://s3.postimg.cc/b6cjsb4bn/Receipt_Excel.png
我仍然需要对不是行项目的行进行一些垃圾清理,但是所有这些仅需要几秒钟,因此不会给我带来太多麻烦.
I still need to do some garbage cleaning on the rows that aren't line items but that all only takes a few seconds so doesn't bother me too much.
感谢在正确的方向上微移@RevJohn,我不会想尝试简单地缩放图像,但是Tesseract改变了世界!
Thanks for the nudge in the right direction @RevJohn, I would not have thought to try simply scaling the image but that made all the difference in the world with Tesseract!
这篇关于需要Tesseract收据扫描建议的文章就介绍到这了,希望我们推荐的答案对大家有所帮助,也希望大家多多支持IT屋!

{kind=link}