矩阵乘法的并行和分布式算法 [英] Parallel and distributed algorithms for matrix multiplication
问题描述
当我查看 矩阵乘法算法的维基百科页面时,问题就来了strong>
它说:
此算法的关键路径长度为
Θ((log n)^2)个步骤,这意味着在拥有无限数量处理器的理想机器上,它将花费大量时间.因此,它在任何实际计算机上的最大可能加速为Θ(n3/((log n)^2)).
(引用来自并行和分布式算法/共享内存并行性"部分.)
由于假设有无限个处理器,所以乘法运算应在O(1)中完成.然后将所有元素加起来,这也应该是一个恒定的时间.因此,最长的关键路径应为 O(1)而不是Θ((log n)^ 2).
我想知道O和Θ之间是否存在差异,我在哪里弄错了?
问题已经解决,非常感谢@Chris Beck.答案应分为两部分.
首先,一个小错误是我不计算求和时间.求和在操作中需要O(log(N))(考虑二进制加法).
第二,正如克里斯指出的那样,非平凡的问题在处理器中需要花费时间O(log(N)).最重要的是,最长的关键路径应该是O(log(N)^2)而不是O(1).
对于O和Θ的混淆,我在 Big_O_Notation_Wikipedia 中找到了答案.
Big O是比较函数的最常用渐近符号,尽管在许多情况下,Big O可以用Big ThetaΘ代替,以渐近地缩小边界.
我对最后的结论是错误的. O(log(N)^2)不在求和和处理器处发生,而是在我们拆分矩阵时发生.感谢@displayName提醒我这一点.此外,克里斯对非平凡问题的回答对于研究并行系统仍然非常有用.感谢下面所有热情的回答者!
此问题有两个方面,即可以完全回答该问题.
- 为什么不能通过引入足够数量的处理器来将运行时带到O(1)?
- 矩阵乘法的关键路径长度如何等于Θ(log 2 n)?
一个个地回答问题.
无限数量的处理器
这一点的简单答案是理解两个术语. 任务粒度和任务依赖性.
- 任务粒度- 表示任务分解的精细程度.即使您有无限个处理器,对于一个问题,最大分解仍然是有限的.
- 任务依赖性- 意味着仅可以顺序执行的步骤是什么.就像,除非您已阅读输入,否则无法修改输入.因此,修改总是要在读取输入之前进行,并且不能与输入并行进行.
因此,对于具有四个步骤A, B, C, D的过程,使得 D依赖于C,C依赖于B,B依赖于A ,则单个处理器将以最快的速度工作作为2个处理器,将与4个处理器一样快,将与无限处理器一样快.
这说明了第一个项目符号.
并行矩阵乘法的关键路径长度
- 如果必须将大小为
n X n的方阵划分为四个大小为[n/2] X [n/2]的块,然后继续划分,直到达到单个元素(或大小为1 X 1的矩阵)为止这种类似树的设计应该是 O(log(n)). - 因此,对于并行矩阵乘法,由于我们必须递归地将大小为n的两个矩阵而不是一个矩阵进行递归除法,直到它们的最后一个元素,所以它花费 O(log 2 n) 时间.
- 实际上,这个界限更严格,不仅是 O(log 2 n),而且是Θ(log 2 n).
如果我们要使用 † Master定理来证明运行时,则可以使用递归来进行计算:
M(n)= 8 * M(n/2)+Θ(对数n)
这是主定理2的情况,运行时间为Θ(log 2 n).
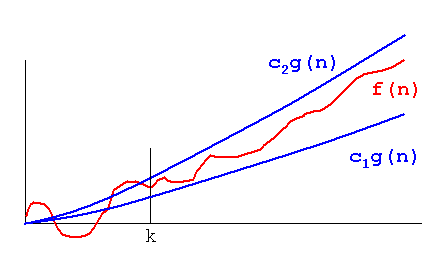
Big O和Theta之间的区别在于,Big O只告诉进程不会超出Big O所提到的范围,而Theta告诉函数不仅具有上限,而且具有下限在Theta中提到.因此,有效地,函数复杂度的 plot 将被夹在同一函数之间,并乘以两个不同的常数,如下图所示,换句话说,该函数将在相同的价格:
图片摘自: http://xlinux.nist .gov/dads/Images/thetaGraph.gif
因此,我想说的是,对于您的情况,您可以忽略该表示法,并且在这两者之间不会被严重地"误认为.
总结...
我想定义另一个术语,称为 Speedup或Parallelism .它定义为最佳顺序执行时间(也称为工作)与并行执行时间的比值.最佳顺序访问时间(已链接至维基百科页面上已给出)为 O (n 3 ).并行执行时间为 O(log 2 n).
因此,速度为= O(n 3 /log 2 n).
>尽管加速看起来如此简单明了,但由于由于移动数据固有的通信成本,在实际情况下实现该目标还是非常困难的.
† 主定理
让 a 为大于或等于1的整数,而 b 为大于1的实数.令 c 为正数实数, d 是非负实数.重复出现以下形式-
当n> 1 时T(n)= a * T(n/b)+ n c
然后为 n 赋予 b 的幂,如果
- Log b a< c,T(n)=Θ(n c );
- Log b a = c,T(n)=Θ(n c * Log n);
- Log b a> c,T(n)=Θ(n log b a ).
The problem comes when I looked up Wikipedia page of Matrix multiplication algorithm
It says:
This algorithm has a critical path length of
Θ((log n)^2)steps, meaning it takes that much time on an ideal machine with an infinite number of processors; therefore, it has a maximum possible speedup ofΘ(n3/((log n)^2))on any real computer.
(The quote is from section "Parallel and distributed algorithms/Shared-memory parallelism.")
Since assuming there are infinite processors, the operation of multiplication should be done in O(1). And then just add all elements up, and this should be a constant time as well. Therefore, the longest critical path should be O(1) instead of Θ((log n)^2).
I was wondering if there is difference between O and Θ and where am I mistaken?
The problem has been solved, big thanks to @Chris Beck. The answer should be separated into two parts.
First, a low mistake is I do not count the time of summation. The summation takes O(log(N)) in operation( think about binary adding ).
Second, as Chris points out, the non-trivial problems takes time O(log(N)) in the processor. Above all, the longest critical path should be O(log(N)^2) instead of O(1).
For confusion of O and Θ, I found the answer in Big_O_Notation_Wikipedia.
Big O is the most commonly used asymptotic notation for comparing functions, although in many cases Big O may be replaced with Big Theta Θ for asymptotically tighter bounds.
I was wrong for the last conclusion. The O(log(N)^2) does not happen at summation and processor, but happen at when we split the matrix. Thanks @displayName for reminding me of this. In addition, Chris' answer for non trivial problem is still very useful for researching parallel system. Thank all warm heart answerers below!
There are two aspects to this question, addressing which the question will be completely answered.
- Why can't we bring the run-time to O(1) by throwing in sufficient number of processors?
- How is the critical path length for Matrix Multiplication equal to Θ(log2n)?
Going after the questions one by one.
Infinite number of processors
The simple answer to this point is in understanding two terms viz. Task Granularity and Task Dependency.
- Task Granularity - implies how fine the task decomposition is. Even if you have infinite processors, the maximum decomposition is still finite for a problem.
- Task Dependency - implies that what are the steps that simply can be performed sequentially only. Like, you cannot modify the input unless you have read it. So modifying will always be preceded by reading of the input and cannot be done in parallel with it.
So, for a process that has four steps A, B, C, D such that D is dependent on C, C is dependent on B and B is dependent on A, then a single processor will work as fast as 2 processors, will work as fast as 4 processors, will work as fast as infinite processors.
This explains the first bullet.
Critical Path Length for Parallel Matrix Multiplication
- If you had to divide a square matrix of size
n X ninto four blocks of size[n/2] X [n/2]each and then continue dividing until you reach down to a single element (or matrix of size1 X 1) the number of levels this tree-like design would have is O(log (n)). - Thus, for matrix multiplication in parallel, since we have to recursively divide not one but two matrices of size n, down to their last element, it takes O(log2n) time.
- In fact, this bound is tighter and is not just O(log2n), but Θ(log2n).
If we go about proving the run-time by using †Master Theorem, we could calculate the same using the recurrence:
M(n) = 8 * M(n/2) + Θ(Log n)
This is case - 2 of Master Theorem and gives the run-time as Θ(log2n).
The difference between Big O and Theta is that Big O only tells that a process won't go above what's mentioned by Big O, while Theta tells that function is not just having an upper bound, but also the lower bound with what's mentioned in Theta. Hence, effectively, the plot of the complexity of the function would be sandwiched between the same function, multiplied with two different constants as depicted in the image below, or in other words, the function will grow at the same rate:
Image taken from: http://xlinux.nist.gov/dads/Images/thetaGraph.gif
So, I'd say that for your case, you can ignore the notation and you are not "gravely" mistaken between the two.
To conclude...
I'd like to define another term called Speedup or Parallelism. It is defined as the ratio of best sequential execution time (also called work) and parallel execution time. The best sequential access time, already given on the wikipedia page you've linked to is O(n3). The parallel execution time is O(log2n).
Hence, the speedup is = O(n3/log2n).
And even though the speedup looks so simple and straightforward, achieving it in actual cases is very difficult due to due to the communication costs that are inherent in moving data.
†Master Theorem
Let a be an integer greater than or equal to 1 and b be a real number greater than 1. Let c be a positive real number and d a nonnegative real number. Given a recurrence of the form -
T (n) = a * T(n/b) + nc when n > 1
then for n a power of b, if
- Logba < c, T (n) = Θ(nc);
- Logba = c, T (n) = Θ(nc * Log n);
- Logba > c, T (n) = Θ(nlogba).
这篇关于矩阵乘法的并行和分布式算法的文章就介绍到这了,希望我们推荐的答案对大家有所帮助,也希望大家多多支持IT屋!

{kind=link}