在上一章中,我们已经了解了如何从twitter源获取数据到HDFS.本章介绍如何从序列生成器获取数据.
要运行本章提供的示例,您需要安装 HDFS 以及 Flume .因此,请先验证Hadoop安装并启动HDFS,然后再继续操作. (请参阅上一章以了解如何启动HDFS.)
我们必须配置源,通道和使用 conf 文件夹中的配置文件进行接收.本章给出的示例使用序列生成器源,内存通道和 HDFS接收器.
它是持续生成事件的源.它维护一个从0开始并以1递增的计数器.它用于测试目的.在配置此来源时,您必须为以下属性提供值 :
频道
来源类型 : seq
我们正在使用内存频道.要配置内存通道,必须为通道类型提供值.下面给出了配置内存通道时需要提供的属性列表 :
type : 它保留了频道的类型.在我们的示例中,类型为MemChannel.
容量 : 它是通道中存储的最大事件数.其默认值为100.(可选)
TransactionCapacity : 它是通道接受或发送的最大事件数.默认值为100.(可选).
此接收器将数据写入HDFS.要配置此接收器,您必须提供以下详细信息.
Channel
type : hdfs
hdfs.path : HDFS中目录的路径,用于存储数据.
我们可以根据场景提供一些可选值.下面给出了我们在应用程序中配置的HDFS接收器的可选属性.
fileType : 这是我们的HDFS文件所需的文件格式. SequenceFile,DataStream 和 CompressedStream 是此流可用的三种类型.在我们的示例中,我们使用 DataStream .
writeFormat : 可以是文本也可以是可写的.
batchSize : 它是在将文件刷新到HDFS之前写入文件的事件数.它的默认值是100.
rollsize : 触发滚动的文件大小.默认值为100.
rollCount : 它是在滚动之前写入文件的事件数.它的默认值是10.
以下是一个示例配置文件.复制此内容并保存为 seq_gen .conf 在Flume的conf文件夹中.
# Naming the components on the current agent SeqGenAgent.sources = SeqSource SeqGenAgent.channels = MemChannel SeqGenAgent.sinks = HDFS # Describing/Configuring the source SeqGenAgent.sources.SeqSource.type = seq # Describing/Configuring the sink SeqGenAgent.sinks.HDFS.type = hdfs SeqGenAgent.sinks.HDFS.hdfs.path = hdfs://localhost:9000/user/Hadoop/seqgen_data/ SeqGenAgent.sinks.HDFS.hdfs.filePrefix = log SeqGenAgent.sinks.HDFS.hdfs.rollInterval = 0 SeqGenAgent.sinks.HDFS.hdfs.rollCount = 10000 SeqGenAgent.sinks.HDFS.hdfs.fileType = DataStream # Describing/Configuring the channel SeqGenAgent.channels.MemChannel.type = memory SeqGenAgent.channels.MemChannel.capacity = 1000 SeqGenAgent.channels.MemChannel.transactionCapacity = 100 # Binding the source and sink to the channel SeqGenAgent.sources.SeqSource.channels = MemChannel SeqGenAgent.sinks.HDFS.channel = MemChannel
浏览Flume主目录并执行如下所示的应用程序.
$ cd $FLUME_HOME $./bin/flume-ng agent --conf $FLUME_CONF --conf-file $FLUME_CONF/seq_gen.conf --name SeqGenAgent
如果一切顺利,源会开始生成序列号,这些序列号将以日志文件的形式推送到HDFS.
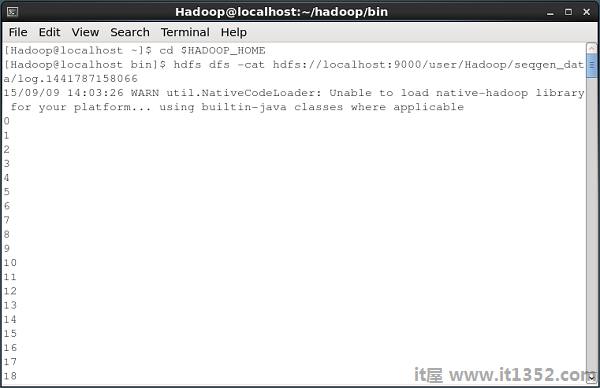
下面给出的是快照命令提示符窗口将序列生成器生成的数据提取到HDFS中.
您可以使用以下URL :
http://localhost:50070/
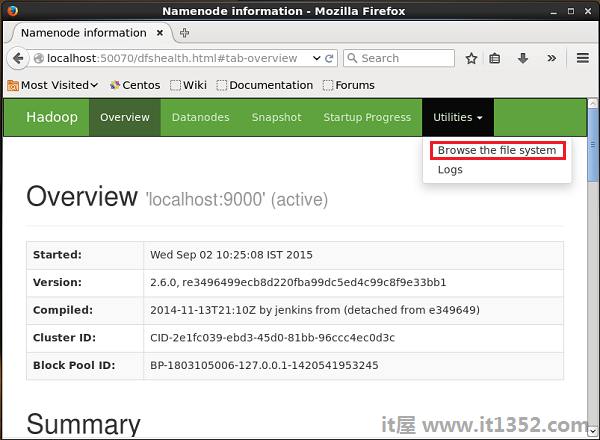
单击右侧名为 Utilities 的下拉列表 - 手边的页面.您可以看到两个选项,如下图所示.
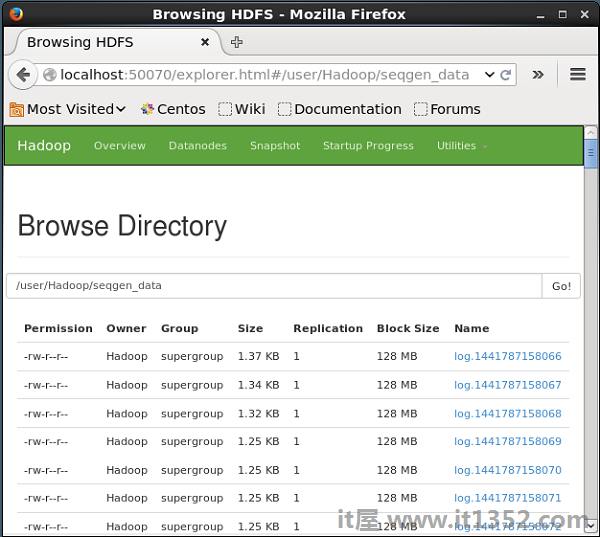
单击浏览文件系统并输入HDFS目录的路径,其中存储了序列生成器生成的数据.
在我们的例如,路径将是/user/Hadoop/seqgen_data/.然后,您可以看到序列生成器生成的日志文件列表,存储在HDFS中,如下所示.
所有这些日志文件都包含顺序格式的数字.您可以使用 cat 命令在文件系统中验证这些文件的内容,如下所示.