Spark引入了一个名为Spark SQL的结构化数据处理编程模块.它提供了一个名为DataFrame的编程抽象,可以作为分布式SQL查询引擎.
以下是Spark SQL的功能 :
集成 : 将SQL查询与Spark程序无缝混合. Spark SQL允许您将结构化数据作为Spark中的分布式数据集(RDD)进行查询,并使用Python,Scala和Java中的集成API.这种紧密集成使得SQL查询与复杂的分析算法一起运行变得容易.
统一数据访问 : 从各种来源加载和查询数据. Schema-RDD提供了一个有效处理结构化数据的单一界面,包括Apache Hive表,镶木地板文件和JSON文件.
Hive兼容性 : 在现有仓库上运行未修改的Hive查询. Spark SQL重用了Hive前端和MetaStore,使您可以完全兼容现有的Hive数据,查询和UDF.只需将其与Hive一起安装即可.
标准连接 : 通过JDBC或ODBC连接. Spark SQL包括具有行业标准JDBC和ODBC连接的服务器模式.
可伸缩性 : 对交互式查询和长查询使用相同的引擎. Spark SQL利用RDD模型来支持中间查询容错,使其可以扩展到大型作业.不要担心使用不同的引擎来获取历史数据.
下图解释了Spark SQL的架构 :
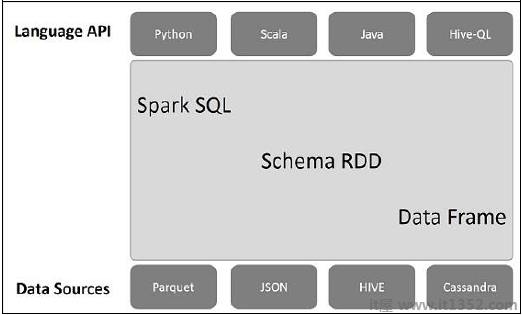
此体系结构包含三个层,即Language API,Schema RDD和Data Sources.
语言API : Spark兼容不同的语言和Spark SQL.它也受这些语言支持 - API(python,scala,java,HiveQL).
Schema RDD : Spark Core设计有称为RDD的特殊数据结构.通常,Spark SQL适用于模式,表和记录.因此,我们可以使用Schema RDD作为临时表.我们可以将此Schema RDD称为数据框架.
数据源 : 通常,spark-core的数据源是文本文件,Avro文件等.但是,Spark SQL的数据源是不同的.这些是Parquet文件,JSON文档,HIVE表和Cassandra数据库.
我们将在后续章节中讨论更多相关内容.