C ++ 20中的协程是什么? [英] What are coroutines in C++20?
问题描述
在抽象层次上,协程将
SIMD(单指令多数据)具有多个执行线程,但只有一个执行状态(仅适用于多个数据)。可以说并行算法有点像这样,因为您有一个在不同数据上运行的程序。
线程具有多个执行线程和多个执行状态。您有一个以上的程序,并且有一个以上的执行线程。
协程具有多个执行状态,但不拥有执行线程。您有一个程序,并且该程序具有状态,但是没有执行线程。
协程的最简单示例是其他语言的生成器或可枚举。
使用伪代码:
函数Generator(){
用于(i = 0至100)
产生i
}
调用 Generator ,并且第一次调用它会返回 0 。它的状态会被记住(多少状态会随着协程的实现而变化),下次您调用它时,它会从中断处继续。因此,下一次返回1。然后2。
最后,它到达循环的结尾并从函数的结尾掉落;协程完成。 (此处发生的变化取决于我们所讨论的语言;在python中,它引发异常)。
协同程序将此功能引入C ++。
协程有两种:堆栈无栈。
无堆栈协程仅在其状态和执行位置存储局部变量。
堆栈式协程存储整个堆栈(如线程)。
无堆栈协程的重量极轻。我阅读的最后一个建议基本上涉及将您的函数重写为类似lambda的形式。所有局部变量都进入对象的状态,并使用标签跳转到协程产生中间结果的位置/从该位置跳转。
产生过程因为协程有点像协作多线程,所以这个值称为收益。
Boost实现了堆栈式协程的实现。它使您可以调用一个函数来为您屈服。堆栈式协程更强大,但也更昂贵。
协程比简单的生成器要多得多。您可以在协程中等待协程,这将使您以一种有用的方式编写协程。
协程就像if,循环和函数调用一样,是另一种结构化的goto,可以让您以更自然的方式表达某些有用的模式(例如状态机)。
C ++中的协程有点有趣。
在最基本的层次上,它为C ++添加了一些关键字: co_return co_await co_yield ,以及与之配合使用的某些库类型。
一个函数在其体内具有一个协程,从而成为协程。因此,从它们的声明中它们与函数是没有区别的。
当在函数体中使用这三个关键字之一时,会发生一些标准的授权检查返回类型和参数,并且函数被转换为协程。此检查告诉编译器函数暂停时在何处存储函数状态。
最简单的协程是生成器:
generator< int> get_integers(int start = 0,int step = 1){
for(int current = start; true; current + = step)
co_yield current;
}
co_yield 暂停函数执行,将状态存储在 generator< int> 中,然后通过<$ c返回当前值 current $ c> generator< int> 。
您可以遍历返回的整数。
co_await 同时允许您将一个协程拼接到另一个。如果您在一个协程中,并且在进行之前需要等待的结果(通常是协程)的结果,则可以在其中进行 co_await 的操作。如果它们准备好了,请立即进行;如果没有,则暂停,直到等待的等待准备就绪为止。
std :: future< std :: expected< std :: string>> load_data(std :: string resource)
{
自动句柄= co_await open_resouce(resource);
while(自动行= co_await read_line(句柄)){
if(std :: optional< std :: string> r = parse_data_from_line(line))
co_return * r;
}
co_return std :: unexpected(resource_lacks_data(resource));
}
load_data 是当命名资源被打开时,协程将生成 std :: future ,并且我们设法解析到找到所需数据的位置。
open_resource 和 read_line s可能是异步协程,它们会打开文件并从中读取行。 co_await 将 load_data 的暂停和就绪状态与其进度联系起来。
C ++协程比这更加灵活,因为它们是作为用户空间类型之上的最小语言功能集实现的。用户空间类型有效地定义了 co_return co_await 和 co_yield 平均值-我见过人们用它来实现monadic可选表达式,这样在空的可选项上的 co_await 会自动将空状态传播到外部可选项:
modified_optional< int> add(modified_optional< int> a,modified_optional< int> b){
return(co_await a)+(co_await b);
}
而不是
std :: optional< int> add(std :: optional< int> a,std :: optional< int> b){
if(!a)return std :: nullopt;
if(!b)返回std :: nullopt;
返回* a + * b;
}
What are coroutines in c++20?
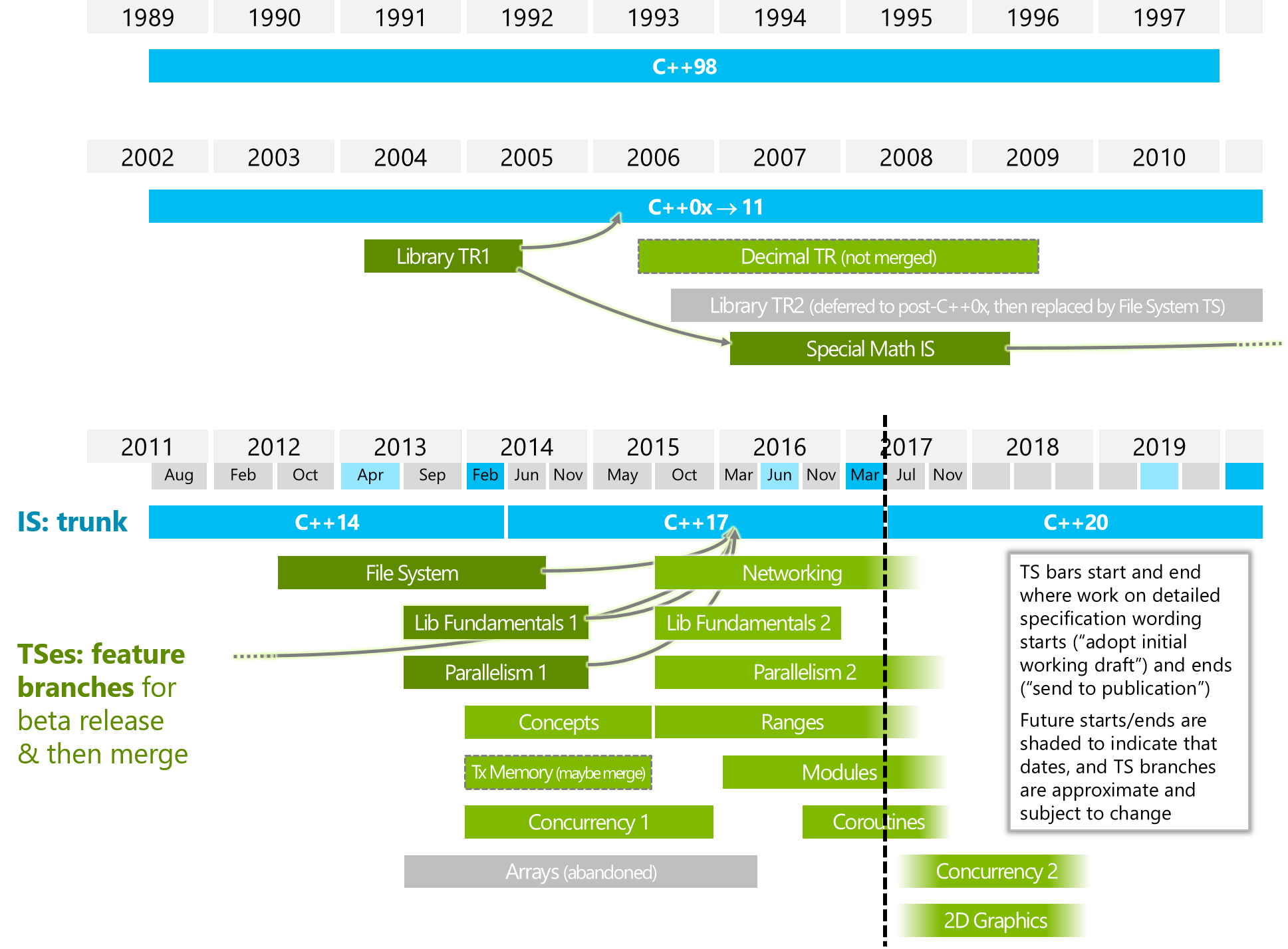
In what ways it is different from "Parallelism2" or/and "Concurrency2" (look into below image)?
The below image is from ISOCPP.
https://isocpp.org/files/img/wg21-timeline-2017-03.png
At an abstract level, Coroutines split the idea of having an execution state off of the idea of having a thread of execution.
SIMD (single instruction multiple data) has multiple "threads of execution" but only one execution state (it just works on multiple data). Arguably parallel algorithms are a bit like this, in that you have one "program" run on different data.
Threading has multiple "threads of execution" and multiple execution states. You have more than one program, and more than one thread of execution.
Coroutines has multiple execution states, but does not own a thread of execution. You have a program, and the program has state, but it has no thread of execution.
The easiest example of coroutines are generators or enumerables from other languages.
In pseudo code:
function Generator() {
for (i = 0 to 100)
produce i
}
The Generator is called, and the first time it is called it returns 0. Its state is remembered (how much state varies with implementation of coroutines), and the next time you call it it continues where it left off. So it returns 1 the next time. Then 2.
Finally it reaches the end of the loop and falls off the end of the function; the coroutine is finished. (What happens here varies based on language we are talking about; in python, it throws an exception).
Coroutines bring this capability to C++.
There are two kinds of coroutines; stackful and stackless.
A stackless coroutine only stores local variables in its state and its location of execution.
A stackful coroutine stores an entire stack (like a thread).
Stackless coroutines can be extremely light weight. The last proposal I read involved basically rewriting your function into something a bit like a lambda; all local variables go into the state of an object, and labels are used to jump to/from the location where the coroutine "produces" intermediate results.
The process of producing a value is called "yield", as coroutines are bit like cooperative multithreading; you are yielding the point of execution back to the caller.
Boost has an implementation of stackful coroutines; it lets you call a function to yield for you. Stackful coroutines are more powerful, but also more expensive.
There is more to coroutines than a simple generator. You can await a coroutine in a coroutine, which lets you compose coroutines in a useful manner.
Coroutines, like if, loops and function calls, are another kind of "structured goto" that lets you express certain useful patterns (like state machines) in a more natural way.
The specific implementation of Coroutines in C++ is a bit interesting.
At its most basic level, it adds a few keywords to C++: co_return co_await co_yield, together with some library types that work with them.
A function becomes a coroutine by having one of those in its body. So from their declaration they are indistinguishable from functions.
When one of those three keywords are used in a function body, some standard mandated examining of the return type and arguments occurs and the function is transformed into a coroutine. This examining tells the compiler where to store the function state when the function is suspended.
The simplest coroutine is a generator:
generator<int> get_integers( int start=0, int step=1 ) {
for (int current=start; true; current+= step)
co_yield current;
}
co_yield suspends the functions execution, stores that state in the generator<int>, then returns the value of current through the generator<int>.
You can loop over the integers returned.
co_await meanwhile lets you splice one coroutine onto another. If you are in one coroutine and you need the results of an awaitable thing (often a coroutine) before progressing, you co_await on it. If they are ready, you proceed immediately; if not, you suspend until the awaitable you are waiting on is ready.
std::future<std::expected<std::string>> load_data( std::string resource )
{
auto handle = co_await open_resouce(resource);
while( auto line = co_await read_line(handle)) {
if (std::optional<std::string> r = parse_data_from_line( line ))
co_return *r;
}
co_return std::unexpected( resource_lacks_data(resource) );
}
load_data is a coroutine that generates a std::future when the named resource is opened and we manage to parse to the point where we found the data requested.
open_resource and read_lines are probably async coroutines that open a file and read lines from it. The co_await connects the suspending and ready state of load_data to their progress.
C++ coroutines are much more flexible than this, as they were implemented as a minimal set of language features on top of user-space types. The user-space types effectively define what co_return co_await and co_yield mean -- I've seen people use it to implement monadic optional expressions such that a co_await on an empty optional automatically propogates the empty state to the outer optional:
modified_optional<int> add( modified_optional<int> a, modified_optional<int> b ) {
return (co_await a) + (co_await b);
}
instead of
std::optional<int> add( std::optional<int> a, std::optional<int> b ) {
if (!a) return std::nullopt;
if (!b) return std::nullopt;
return *a + *b;
}
这篇关于C ++ 20中的协程是什么?的文章就介绍到这了,希望我们推荐的答案对大家有所帮助,也希望大家多多支持IT屋!

{kind=link}