鉴于音频流,发现当门抨击(声pressure水平计算?) [英] Given an audio stream, find when a door slams (sound pressure level calculation?)
问题描述
不是不像拍探测器(拍拍上!拍手鼓掌的拍拍了!拍手鼓掌的拍拍上拍断,梆子!拍手鼓掌)我需要检测一扇门关闭时。这是在车辆中,这比一个房间或家庭门更容易:
Not unlike a clap detector ("Clap on! clap clap Clap off! clap clap Clap on, clap off, the Clapper! clap clap ") I need to detect when a door closes. This is in a vehicle, which is easier than a room or household door:
听:<一href="http://ubasics.com/so/van_driver_door_closing.wav">http://ubasics.com/so/van_driver_door_closing.wav
看:

这是采样的16位4kHz的,我想避免大量处理样品或储存。
It's sampling at 16bits 4khz, and I'd like to avoid lots of processing or storage of samples.
当你看到它的大胆或另一种波形工具,这是相当独特的,而且几乎总是剪辑由于车辆的增加,声音pressure - 甚至在Windows和其他的门是打开的:
When you look at it in audacity or another waveform tool it's quite distinctive, and almost always clips due to the increase in sound pressure in the vehicle - even when the windows and other doors are open:
听:<一href="http://ubasics.com/so/van_driverdoorclosing_slidingdoorsopen_windowsopen_engineon.wav">http://ubasics.com/so/van_driverdoorclosing_slidingdoorsopen_windowsopen_engineon.wav
看:

我希望有一个相对简单的算法,将采取读数4kHz的,8位,并保持轨道的稳定状态。当算法检测到的A声级显著的增加,将标记的地方。
I expect there's a relatively simple algorithm that would take readings at 4kHz, 8 bits, and keep track of the 'steady state'. When the algorithm detects a significant increase in the sound level it would mark the spot.
- 你有什么想法?
- 你将如何检测到这一事件?
- 是否有$声音pressure水平计算了C $ C的例子,可以帮助?
- 我可以不用那么频繁取样(1kHz时或更慢?)
更新:与倍频播放(开源数值分析 - 类似于Matlab的),并查看是否均方根会给我什么,我需要(这会导致一些非常相似的SPL)
Update: Playing with Octave (open source numerical analysis - similar to Matlab) and seeing if the root mean square will give me what I need (which results in something very similar to the SPL)
UPDATE2:计算的RMS发现门上贴着容易在简单情况:

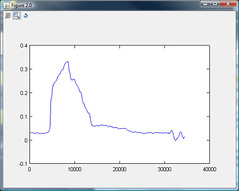
/>
现在我只需要看看的疑难杂症(收音机,热/空气高,等等)。在恒虚警看起来非常有趣 - 我知道我将不得不使用一个自适应算法,和恒虚警率当然符合该法案
Update2: Computing the RMS finds the door close easily in the simple case:
Now I just need to look at the difficult cases (radio on, heat/air on high, etc). The CFAR looks really interesting - I know I'm going to have to use an adaptive algorithm, and CFAR certainly fits the bill.
推荐答案
查看源音频文件的截图,一个简单的方法来检测声音水平的变化会做一个的numerical整合找出波的能量在特定的时间。
Looking at the screenshots of the source audio files, one simple way to detect a change in sound level would be to do a numerical integration of the samples to find out the "energy" of the wave at a specific time.
一个粗略的算法是:
- 了将样本分为部分
- 在计算各部分的能量
- 拿previous窗口和当前窗口 之间的能量之比
- 如果该比值超过某个阈值,确定出现了突然的巨响。
- Divide the samples up into sections
- Calculate the energy of each section
- Take the ratio of the energies between the previous window and the current window
- If the ratio exceeds some threshold, determine that there was a sudden loud noise.
伪code
samples = load_audio_samples() // Array containing audio samples
WINDOW_SIZE = 1000 // Sample window of 1000 samples (example)
for (i = 0; i < samples.length; i += WINDOW_SIZE):
// Perform a numerical integration of the current window using simple
// addition of current sample to a sum.
for (j = 0; j < WINDOW_SIZE; j++):
energy += samples[i+j]
// Take ratio of energies of last window and current window, and see
// if there is a big difference in the energies. If so, there is a
// sudden loud noise.
if (energy / last_energy > THRESHOLD):
sudden_sound_detected()
last_energy = energy
energy = 0;
我要补充一点,我还没有试过这样的免责声明。
要,而无需所有记录的第一样品进行该方法应该是可能的。只要有一些长度(在示例WINDOW_SIZE )缓冲液,数值积分可被执行以计算声音的部分的能量。这并不意味着,然而,有将在处理的延迟,依赖于 WINDOW_SIZE 的长度。确定好长度部分声音的是另外一个问题。
This way should be possible to be performed without having the samples all recorded first. As long as there is buffer of some length (WINDOW_SIZE in the example), a numerical integration can be performed to calculate the energy of the section of sound. This does mean however, that there will be a delay in the processing, dependent on the length of the WINDOW_SIZE. Determining a good length for a section of sound is another concern.
如何拆分成段
在第一音频文件,看来关门的声音的持续时间是0.25秒,所以用于数值积分窗口也许应该在大多数半,或甚至更喜欢的十分之一,所以沉默和突然的声音之间的差异可以注意到,即使窗口是无声部分和噪声部分之间的重叠。
In the first audio file, it appears that the duration of the sound of the door closing is 0.25 seconds, so the window used for numerical integration should probably be at most half of that, or even more like a tenth, so the difference between the silence and sudden sound can be noticed, even if the window is overlapping between the silent section and the noise section.
例如,如果积分窗口为0.5秒,并且第一窗口被覆盖沉默的0.25秒和0.25秒关门的,和第二窗口被覆盖关门0.25秒和0.25秒的沉默,它可能出现声音的两个部分具有噪声的相同电平,因此,不会触发声音检测。我想有一个短暂的窗口会有所缓解这个问题。
For example, if the integration window was 0.5 seconds, and the first window was covering the 0.25 seconds of silence and 0.25 seconds of door closing, and the second window was covering 0.25 seconds of door closing and 0.25 seconds of silence, it may appear that the two sections of sound has the same level of noise, therefore, not triggering the sound detection. I imagine having a short window would alleviate this problem somewhat.
然而,具有一个窗口,太短将意味着上升的声音可能不完全配合到一个窗口,并且其可以apppear存在的相邻段之间的能量几乎没有差别,这可能导致声音不容错过。
However, having a window that is too short will mean that the rise in the sound may not fully fit into one window, and it may apppear that there is little difference in energy between the adjacent sections, which can cause the sound to be missed.
我相信 WINDOW_SIZE 和阈值都将不得不凭经验为这是怎么回事声音确定被检测到。
I believe the WINDOW_SIZE and THRESHOLD are both going to have to be determined empirically for the sound which is going to be detected.
为了确定多少样本,该算法将需要保存在内存中,让我们说,在 WINDOW_SIZE 是关门的声音1/10 ,这是约0.025秒。在4kHz的采样速率,即100个样本。这似乎是不太多的存储器要求。使用16位的样本是200个字节。
For the sake of determining how many samples that this algorithm will need to keep in memory, let's say, the WINDOW_SIZE is 1/10 of the sound of the door closing, which is about 0.025 second. At a sampling rate of 4 kHz, that is 100 samples. That seems to be not too much of a memory requirement. Using 16-bit samples that's 200 bytes.
优势/劣势
此方法的优点是可以用简单的整数运算来进行,如果源音频馈送中作为整数的处理。美中不足的是,如已经提到的,该实时处理会产生延迟,根据所集成的区域的大小。
The advantage of this method is that processing can be performed with simple integer arithmetic if the source audio is fed in as integers. The catch is, as mentioned already, that real-time processing will have a delay, depending on the size of the section that is integrated.
有几个问题,我能想到的这个方法:
There are a couple of problems that I can think of to this approach:
- 如果背景噪声太大,在背景噪声和关门之间的能量差也不会很容易区分,并且它可能不能够检测到门关闭。
- 在任何突然的噪声,如拍手,可以被看作是门正在关闭。
也许,组合的建议,在其他的答案,如试图分析关门使用傅立叶分析,这将需要更多的处理,但将使它更不易出错的频率签名。
Perhaps, combining the suggestions in the other answers, such as trying to analyze the frequency signature of the door closing using Fourier analysis, which would require more processing but would make it less prone to error.
它可能会采取一些试验找到一种方法来解决这个问题了。
It's probably going to take some experimentation before finding a way to solve this problem.
这篇关于鉴于音频流,发现当门抨击(声pressure水平计算?)的文章就介绍到这了,希望我们推荐的答案对大家有所帮助,也希望大家多多支持IT屋!
