在数据存储的上下文中,序列化是将数据结构或对象状态转换为可以存储(例如,在文件或内存缓冲区中)或稍后传输和重构的格式的过程.
在序列化中,对象被转换为可以存储的格式,以便以后能够对其进行反序列化,并从序列化格式重新创建原始对象.
Pickling是将Python对象层次结构转换为要写入文件的字节流(通常不是人类可读的)的过程,这也称为序列化.取消是反向操作,将字节流转换回工作的Python对象层次结构.
Pickle是操作上最简单的存储对象的方法. Python Pickle模块是一种面向对象的方式,可以直接以特殊的存储格式存储对象.
Pickle可以非常轻松地存储和复制字典和列表.
存储对象属性并将它们恢复到同一个状态.
它不保存对象代码.只有它的属性值.
它不能存储文件句柄或连接套接字.
总之我们可以说, pickling是一种在文件中存储和检索数据变量的方法,其中变量可以是列表,类等.
要选择必须减去的东西;
import pickle
将变量写入文件,类似于
pickle.dump(mystring, outfile, protocol),
其中第3个参数协议是可选
要取消你必须和减去的东西;
导入泡菜
将变量写入文件,类似于
myString = pickle.load(inputfile)
pickle界面提供了四种不同的方法.
dump() : dump()方法序列化为一个打开的文件(类似文件的对象).
dumps() : 序列化为字符串
load() : 从类似开放的对象反序列化.
loads() : 从字符串反序列化.
根据以上程序,下面是"酸洗"的示例.
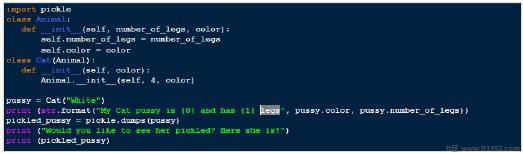
My Cat pussy is White and has 4 legs Would you like to see her pickled? Here she is! b'\x80\x03c__main__\nCat\nq\x00)\x81q\x01}q\x02(X\x0e\x00\x00\x00number_of_legsq\x03K\x04X\x05\x00\x00\x00colorq\x04X\x05\x00\x00\x00Whiteq\x05ub.'
因此,在上面的示例中,我们创建了一个Cat类的实例,然后我们将它腌制,将我们的"Cat"实例转换为一个简单的字节数组.
这样我们就可以轻松地将字节数组存储在二进制文件或数据库字段中,并在以后从存储支持中将其恢复为原始格式.
如果你想要用pickle对象创建一个文件,你可以使用dump()方法(而不是dumps *()* one)传递一个打开的二进制文件,并且pickling结果将自动存储在文件中.
[….] binary_file = open(my_pickled_Pussy.bin', mode='wb') my_pickled_Pussy = pickle.dump(Pussy, binary_file) binary_file.close()
采用二进制数组并将其转换为对象层次结构的过程称为unpickling.
通过使用pickle模块的load()函数完成unpickling过程并返回一个完整的对象来自简单字节数组的层次结构.
让我们使用前面例子中的加载函数.
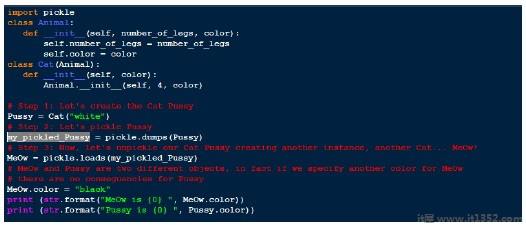
MeOw is black Pussy is white
JSON(JavaScript Object Notation)已经成为Python标准库的一部分,是一种轻量级的数据交换格式.人类很容易读写.它很容易解析和生成.
由于它的简单性,JSON是我们存储和交换数据的一种方式,它通过其JSON语法实现,并在许多Web中使用应用.因为它是人类可读的格式,这可能是在数据传输中使用它的原因之一,除了它在使用API时的有效性.
JSON格式的一个例子数据如下:
{"EmployID": 40203, "Name": "Zack", "Age":54, "isEmployed": True}Python使得处理Json文件变得简单.为此目的而使用的模块是JSON模块.这个模块应该包含在你的Python安装中(内置).
让我们看看我们如何将Python字典转换为JSON并将其写入文本文件.
读取JSON意味着将JSON转换为Python值(对象). json库将JSON解析为Python中的字典或列表.为了做到这一点,我们使用loads()函数(从字符串加载),如下:&;


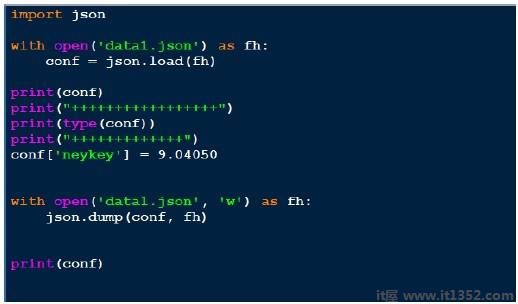
下面是一个示例json文件,
data1.json
{"menu": {
"id": "file",
"value": "File",
"popup": {
"menuitem": [
{"value": "New", "onclick": "CreateNewDoc()"},
{"value": "Open", "onclick": "OpenDoc()"},
{"value": "Close", "onclick": "CloseDoc()"}
]
}
}}以上内容(Data1 .json)看起来像一个传统的字典.我们可以使用pickle来存储这个文件,但是它的输出不是人类可读的形式.
JSON(Java脚本对象通知)是一种非常简单的格式,这是它的原因之一人气.现在让我们通过下面的程序查看json输出.
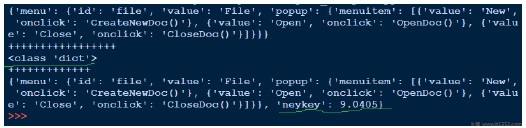
上面我们打开用于读取的json文件(data1.json),获取文件处理程序并传递给json.load并获取对象.当我们尝试打印对象的输出时,它与json文件相同.虽然对象的类型是字典,但它作为Python对象出现.当我们看到这个泡菜时,写入json很简单.上面我们加载json文件,添加另一个键值对并将其写回到同一个json文件中.现在,如果我们看到data1.json,它看起来不同.i.e.与我们之前看到的格式不同.
要使我们的输出看起来相同(人类可读的格式),请将几个参数添加到程序的最后一行,
json.dump(conf,fh,indent = 4,separators =(',',':'))与pickle类似,我们可以使用dumps打印字符串并使用load加载.下面是一个例子,
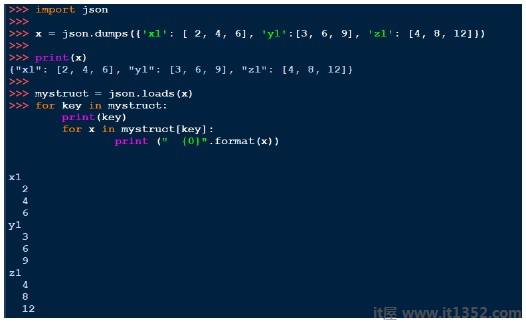
YAML可能是所有编程语言中最人性化的数据序列化标准.
Python yaml模块称为pyaml
YAML是JSON : 的替代品;
人类可读代码 : YAML是最易读的格式,因此即使其首页内容也会在YAML中显示,以表明这一点.
压缩代码 : 在YAML中,我们使用空格缩进来表示结构而非括号.
关系数据的语法 : 对于内部引用,我们使用锚点(&)和别名(*).
广泛使用的区域之一是查看/编辑数据结构 : 例如配置文件,在调试期间转储和文档标题.
作为yaml不是内置模块,我们需要手动安装它.在Windows机器上安装yaml的最佳方法是通过pip.在windows终端上运行以下命令安装yaml,
pip install pyaml (Windows machine) sudo pip install pyaml (*nix and Mac)
在运行上面的命令时,屏幕将根据当前的最新版本显示如下内容.
Collecting pyaml Using cached pyaml-17.12.1-py2.py3-none-any.whl Collecting PyYAML (from pyaml) Using cached PyYAML-3.12.tar.gz Installing collected packages: PyYAML, pyaml Running setup.py install for PyYAML ... done Successfully installed PyYAML-3.12 pyaml-17.12.1
要测试它,转到Python shell并导入yaml模块,
import yaml,如果没有找到错误,那么我们可以说安装成功.
安装pyaml后,让我们看下面的代码,
script_yaml1.py
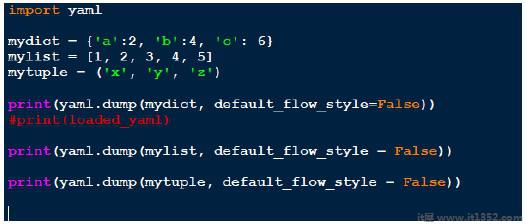
上面我们创建了三种不同的数据结构,字典,列表和元组.在每个结构上,我们做yaml.dump.重要的一点是输出如何在屏幕上显示.

字典输出看起来很干净.ie. key:value.
分隔不同对象的空格.
列表标有破折号( - )
首先用!! Python/元组表示元组,然后用与列表相同的格式表示.
加载yaml文件
所以让我们说我有一个yaml文件,其中包含,
--- # An employee record name: Raagvendra Joshi job: Developer skill: Oracle employed: True foods: - Apple - Orange - Strawberry - Mango languages: Oracle: Elite power_builder: Elite Full Stack Developer: Lame education: 4 GCSEs 3 A-Levels MCA in something called com
现在让我们编写一个代码来通过yaml.load函数加载这个yaml文件.下面是相同的代码.
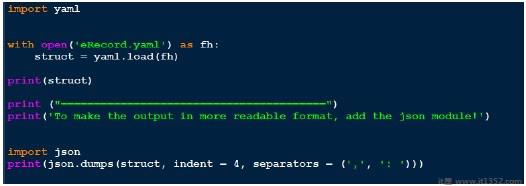
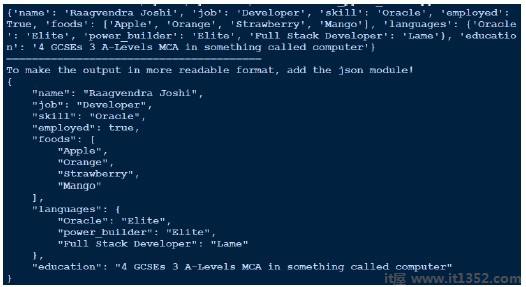
作为输出看起来不那么可读,我最后通过使用json来美化它.比较我们得到的输出和我们的实际yaml文件.
软件开发最重要的一个方面是调试.在本节中,我们将看到使用内置调试器或第三方调试器进行Python调试的不同方法.
模块PDB支持设置断点.断点是程序的故意暂停,您可以在其中获得有关程序状态的更多信息.
要设置断点,请插入行
pdb.set_trace()
pdb_example1.py import pdb x = 9 y = 7 pdb.set_trace() total = x + y pdb.set_trace()
我们在这个程序中插入了几个断点.程序将在每个断点处暂停(pdb.set_trace()).要查看变量内容,只需键入变量名称.
c:\Python\Python361>Python pdb_example1.py > c:\Python\Python361\pdb_example1.py(8)<module>() -> total = x + y (Pdb) x 9 (Pdb) y 7 (Pdb) total *** NameError: name 'total' is not defined (Pdb)
按c或继续执行程序直到下一个断点.
(Pdb) c --Return-- > c:\Python\Python361\pdb_example1.py(8)<module>()->None -> total = x + y (Pdb) total 16
最终,你需要调试更大的程序 - 使用的程序子程序.有时候,你试图找到的问题将存在于子程序中.考虑以下程序.
import pdb def squar(x, y): out_squared = x^2 + y^2 return out_squared if __name__ == "__main__": #pdb.set_trace() print (squar(4, 5))
现在运行上面的程序,
c:\Python\Python361>Python pdb_example2.py > c:\Python\Python361\pdb_example2.py(10)<module>() -> print (squar(4, 5)) (Pdb)
我们可以使用?获取帮助,但是箭头表示即将执行的行.在这一点上,点击 s 进入该行是有帮助的.
(Pdb) s --Call-- >c:\Python\Python361\pdb_example2.py(3)squar() -> def squar(x, y):
这是对函数的调用.如果您想要了解代码中的位置,请尝试l :
(Pdb) l 1 import pdb 2 3 def squar(x, y): 4 -> out_squared = x^2 + y^2 5 6 return out_squared 7 8 if __name__ == "__main__": 9 pdb.set_trace() 10 print (squar(4, 5)) [EOF] (Pdb)
你可以点击n到前进到下一行.此时,您位于out_squared方法内,并且可以访问函数.i.e中声明的变量. x和y.
(Pdb) x 4 (Pdb) y 5 (Pdb) x^2 6 (Pdb) y^2 7 (Pdb) x**2 16 (Pdb) y**2 25 (Pdb)
所以我们可以看到^运算符不是我们想要的而是我们需要使用**运算符来做正方形.
这样我们可以在函数/方法中调试我们的程序.
自Python 2.3版以来,日志记录模块已成为Python标准库的一部分.由于它是一个内置模块,所有Python模块都可以参与日志记录,因此我们的应用程序日志可以包含您自己的消息,该消息与来自第三方模块的消息集成在一起.它提供了很多灵活性和功能.
诊断记录 : 它记录与应用程序操作相关的事件.
审计记录 : 它记录事件以进行业务分析.
消息的写入和记录级别为"severity"&minu
DEBUG(debug()) : 用于开发的诊断信息.
INFO(info()) : 标准的"进度"消息.
警告(警告()) : 检测到非严重问题.
错误(错误()) : 遇到错误,可能是严重的.
CRITICAL(critical()) : 通常是一个致命的错误(程序停止).
让我们看看下面的简单程序,
import logging
logging.basicConfig(level=logging.INFO)
logging.debug('this message will be ignored') # This will not print
logging.info('This should be logged') # it'll print
logging.warning('And this, too') # It'll print上面我们记录严重性级别的消息.首先我们导入模块,调用basicConfig并设置日志记录级别.我们上面设置的级别是INFO.然后我们有三个不同的语句:debug语句,info语句和警告语句.
INFO:root:This should be logged WARNING:root:And this, too
因为info语句低于debug语句,我们无法看到调试消息.要在Output终端中获取调试语句,我们需要更改的是basicConfig级别.
logging.basicConfig(level = logging. DEBUG)
在输出中我们可以看到,
DEBUG:root:this message will be ignored INFO:root:This should be logged WARNING:root:And this, too
此外,默认行为意味着如果我们不设置任何日志记录级别是警告.只需注释掉上面程序的第二行并运行代码.
#logging.basicConfig(level = logging.DEBUG)
WARNING:root:And this, too
内置日志记录级别的Python实际上是整数.
>>> import logging >>> >>> logging.DEBUG 10 >>> logging.CRITICAL 50 >>> logging.WARNING 30 >>> logging.INFO 20 >>> logging.ERROR 40 >>>
我们还可以将日志消息保存到文件中.
logging.basicConfig(level = logging.DEBUG, filename = 'logging.log')
现在所有日志消息都将成为文件(logging.log)您当前的工作目录而不是屏幕.这是一个更好的方法,因为它允许我们对我们得到的消息进行后期分析.
我们还可以使用我们的日志消息设置日期戳.
logging.basicConfig(level=logging.DEBUG, format = '%(asctime)s %(levelname)s:%(message)s')
输出结果如下,
2018-03-08 19:30:00,066 DEBUG:this message will be ignored 2018-03-08 19:30:00,176 INFO:This should be logged 2018-03-08 19:30:00,201 WARNING:And this, too
基准测试或剖析基本上是为了测试代码的执行速度和瓶颈在哪里?这样做的主要原因是优化.
Python附带一个名为timeit的内置模块.您可以使用它来计算小代码片段的时间. timeit模块使用特定于平台的时间函数,以便您获得最准确的时间.
因此,它允许我们比较每个代码的两个代码,然后优化脚本为了获得更好的性能.
timeit模块有一个命令行界面,但它也可以导入.
有两种方法可以调用a脚本.让我们首先使用脚本,为此运行以下代码并查看输出.
import timeit
print ( 'by index: ', timeit.timeit(stmt = "mydict['c']", setup = "mydict = {'a':5, 'b':10, 'c':15}", number = 1000000))
print ( 'by get: ', timeit.timeit(stmt = 'mydict.get("c")', setup = 'mydict = {"a":5, "b":10, "c":15}', number = 1000000))by index: 0.1809192126703489 by get: 0.6088525265034692
上面我们使用两种不同的方法.ie通过下标并获取访问字典键值.我们执行语句100万次,因为它对于非常小的数据执行得太快.现在,与get相比,我们可以更快地看到索引访问.我们可以多次运行代码,并且时间执行会略有不同,以便更好地理解.
另一种方法是在命令行中运行上述测试.让我们这样做,
c:\Python\Python361>Python -m timeit -n 1000000 -s "mydict = {'a': 5, 'b':10, 'c':15}" "mydict['c']"
1000000 loops, best of 3: 0.187 usec per loop
c:\Python\Python361>Python -m timeit -n 1000000 -s "mydict = {'a': 5, 'b':10, 'c':15}" "mydict.get('c')"
1000000 loops, best of 3: 0.659 usec per loop根据您的系统硬件以及系统中当前运行的所有应用程序,上述输出可能会有所不同./p>
下面我们可以使用timeit模块,如果我们想调用一个函数.因为我们可以在函数中添加多个语句来测试.
import timeit
def testme(this_dict, key):
return this_dict[key]
print (timeit.timeit("testme(mydict, key)", setup = "from __main__ import testme; mydict = {'a':9, 'b':18, 'c':27}; key = 'c'", number = 1000000))0.7713474590139164