在上一章中,我们已经了解了如何将文本添加到现有PDF文档中.在本章中,我们将讨论如何从现有PDF文档中读取文本.
提取文本是一个PDF框库的主要功能.您可以使用 PDFTextStripper 类的 getText()方法提取文本.此类提取给定PDF文档中的所有文本.
以下是从现有PDF文档中提取文本的步骤.
使用 PDDocument 类的静态方法 load()加载现有PDF文档.此方法接受文件对象作为参数,因为这是一个静态方法,您可以使用类名调用它,如下所示.
File file = new File("path of the document")
PDDocument document = PDDocument.load(file);PDFTextStripper 类提供检索方法因此,PDF文档中的文本实例化如下所示.
PDFTextStripper pdfStripper = new PDFTextStripper();
您可以使用PDF文档读取/检索页面内容 PDFTextStripper 类的 getText()方法.对于此方法,您需要将文档对象作为参数传递.此方法检索给定文档中的文本并以String对象的形式返回.
String text = pdfStripper.getText(document) ;
最后,使用关闭() PDDocument类的方法如下所示.
document.close();
假设我们有一个PDF文档,其中包含一些文本,如下所示.
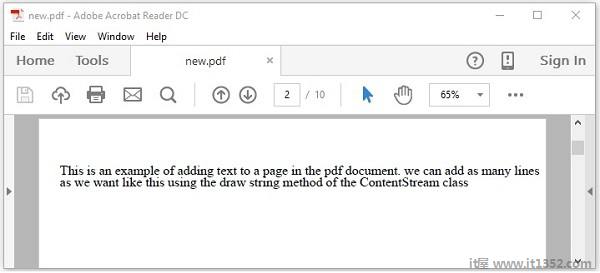
此示例演示如何从上述PDF文档中读取文本.在这里,我们将创建一个Java程序并加载名为 new.pdf 的PDF文档,该文档保存在路径 C:/PdfBox_Examples/中.将此代码保存在名为 ReadingText.java 的文件中.
import java.io.File;
import java.io.IOException;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.text.PDFTextStripper;
public class ReadingText {
public static void main(String args[]) throws IOException {
//Loading an existing document
File file = new File("C:/PdfBox_Examples/new.pdf");
PDDocument document = PDDocument.load(file);
//Instantiate PDFTextStripper class
PDFTextStripper pdfStripper = new PDFTextStripper();
//Retrieving text from PDF document
String text = pdfStripper.getText(document);
System.out.println(text);
//Closing the document
document.close();
}
}使用以下命令从命令提示符编译并执行保存的Java文件.
javac ReadingText.java java ReadingText
执行时,上面的程序从给定的PDF文档中检索文本并显示如下所示.
这是一个向页面添加文本的示例pdf文件.我们可以使用ContentStream类的ShowText()方法添加尽可能多的 行.